Using a sample data set to create and test a decision tree model.
Introduction
Welcome to my blog and thanks for dropping by!
Today, I have my second installment in my decision tree blog series. I’m going to create and run a model leveraging decision trees using data I found on a public data repository. Hopefully you saw part one in this series as it will be pretty important. For a quick reminder, I am going to use the gini metric to make my tree. Let’s begin!
Data Preparation
My data concerns wine quality. I picked this data set because it was a relatively basic data set and was pretty clean to begin. My only important preprocessing was running feature selection to cut down from ten features to five predictive feature. I also binned all my features as either a zero or one to make life easier. That means that instead of having a continuous measure between, say 1 and 100, it instead becomes 0 for lower and 1 for higher. Thankfully, this did not sacrifice model accuracy that much. Also, just to keep things simple, I decided to only look at 150 rows of data so things don’t get out of control. I also wrote the following function for calculating gini:
Here is a function that is built on top of that function just to make things a bit easier (it was cut off a bit):
The function above will allow me to easily go into different branches of each tree while doing very little manual computer programming.
By the way… here is a preview of my data containing five predictive features:
Building My Tree
Let’s start with the base gini values for the five predictive features in terms of their effect on the target feature of quality.
Now, we enter the volatile acidity 0 and volatile acidity 1 worlds:
Ok, so what does all this mean? Assuming we take the value of zero for volatile acidity, and as we’ll see – that is the far more interesting path, our next branch to look at would be pH. Afterward we dive into pH 1 and pH 0 and so on…
Now that we have got a feel of what this tree is going to look like in terms of how we set up our calculations along each branch, I am going to just do the rest by myself and post some final results. There are going to be a lot of branches and looking at every single one will get boring very quickly.
A couple notes:
One: part of this project involved upsampling a minority target class. I did a whole lot of work and basically finished my tree but had to do it all over again because of target class imbalance. Don’t neglect about this key part of the modeling process (if necessary) or your models will be incomplete and inacurate!
Two: I am going to post my model in the form of an Excel table showing all the paths of the tree. You will most likely have no way of knowing this, unless you look at the data (https://www.kaggle.com/uciml/red-wine-quality-cortez-et-al-2009) and go through the same pre-processing I did (which was rather non-traditional), but not all the subsets displayed actually exist. So I will have some branches from the tree written out in my Excel table that are not actually part of any tree at all. When that happens, I took a step back and just saw what things would look like in the absence of that feature. Some combinations of characteristics of wine (that’s what my data concerns) don’t exist in the 150 rows I chose at random to build my tree. Consequently, when you view my tree, you should focus on the order of features as opposed to the particular combinations, as I imagine that I will end up listing every possible combination possible. The order that the features appear tell the story of what feature was most predictive at each branch. Don’t get lost in all the details.
Here is what I came up with (I color coded each feature to make it easy to follow):
In case you are wondering, the first feature in my tree, volatile acidity, was so predictive that any time it was equal to 1, the conclusion was 0 for the target variable.
So now it’s time to see if this actually works; we need test data. I used a basic train-test-split. That’s data science for language for artificially separating data to specifically not build a model on and instead use for testing purposes. I’ll be transparent and display my test data set. At this point, I don’t know how well my model is going to work so we’re all in this together in a sense.
So now that we have the logic in place and you have seen all my test data, you could theoretically “run the model” yourself and follow each path outlined above and see how the data fits in. That sounds like a lot of work, though. Here is what it would look like if you did all that work:
At 68% accuracy, I am proud of this model. If we eliminate the binary binning and add more of the original data, this number will go up to ~77%.
Conclusion
Using the gini metric and a real data set (and a little bit of preprocessing magic), we were able to create a basic decision tree. Considering the circumstances, it was fairly accurate. Decision trees are great because they are fairly simple conceptually and the math is not that hard either.
Understanding how to build a decision tree using statistical methods.
Introduction
Thanks for visiting my blog today!
Life is complex and largely guided by the decisions we make. Decisions are also complex and are usually the result of a cascade of other decisions and logic flowing through our heads. Just like we all make various decision trees in our heads (whether we actively think about them or not) to guide our decisions, machines can also leverage a sequence of decisions (based on logical rules) to come to a conclusion. Example: I go to a Blackhawks game. The Blackhawks are tied with 2 minutes left. It’s a preseason game. Do I leave early to avoid the parking lot they call “traffic” and catch the rest on TV or radio, or do I stay and watch a potential overtime game (which is always exciting). There’s nothing on the line for the Blackhawks (and therefore their fan base) but I paid money and took a chunk of time out of my day to see Patrick Kane light up the scoreboard and sing along to Chelsea Dagger. There are few experiences that are as exciting as a last second or overtime / extra-time game winning play and I know from past live experience. Nevertheless, we are only scratching the surface of what factors may or may not be at play. What if I am a season ticket holder? I probably would just leave early. What if I come to visit my cousins in Chicago for 6 individual (and separate) weeks every year? I might want to stay as it’s likely that some weeks I visit there won’t even be a game. Right there, I built a machine learning model in front of your eyes (sort of). My de-facto features are timeInChicago, futureGamesAttending, preseasonSeasonPosteason, timeAvailable, gameSituation. (These are the ones I made up after looking back at build-up to this point and think they work well – I’m sure others will think of different ways to contextualize this problem). My target feature can be binary; stay or leave. It can also be continuous; time spent at game. It can also be multi-class; periods stayed in (1, 2, or 3). This target feature ambiguity can change the problem depending on one’s philosophy. Whether you realize this or not, you are effectively creating a decision tree. It may not feel like all these calculations and equations are running through your head and you may not even take that long or incur that much stress when making a decision, but you’re using that decision tree logic.
In today’s blog we are going to look at the concepts surrounding a decision tree and discuss how they are built and make decisions. In my next blog in this series (which may or may not be my next blog I write), I will take the ideas discussed here and show an application on real-world data. Following that, I will build a decision tree model from scratch in python. The blog after that will focus on how to take the basic decision tree model to the next level using a random forest. After that blog, I will show you how to leverage and optimize decision trees and random forests in machine learning models using python. There may be more on the way, but that’s the plan for now.
I’d like to add that I think I’m going to learn a lot myself in this blog as it’s important, especially during a job interview, to explain concepts. Many of you who may know python may know ways to quickly create and run a decision tree model. However, in my opinion, it is equally as important (if not more) to understand the concepts and to be able explain what things like entropy and information gain are (some main concepts to be introduced later). Concepts generally stay in place, but coding tends to evolve.
Let’s get to the root of the issue.
How Do We Begin?
It makes sense that we want to start with the most decisive feature. Say a restaurant only serves ribeye steak on Monday. I go to the restaurant and have to decide what to order, and I really like ribeye steak. How do I begin my decision tree? The first thing I ask myself is if it’s Monday or not. If it’s Monday, I will always get the steak. Otherwise, I won’t be able to order that steak. In the non-Monday universe, aka the one where I will be guaranteed to not get the steak, the whole tree changes when I pick what to eat. So we want to start with the most decisive features and work our way down to the least decisive features. Sometimes the trees will not have the same branches at the same time. Say the features (in this restaurant example) are day of the week, time of day, people with me eating, and cash in my pocket. Now I really like steak. So much so that every Monday I am willing to spend any amount of money for the ribeye steak (I suppose in this example, the cost is variable). For other menu items, I may concern myself with price a bit more. Price doesn’t matter in the presence of value but becomes a big issue in the absence of value. So, in my example: money in pocket will be more decisive in the non-Monday example than the Monday example and therefore find itself at a different place in the tree. The way this presents itself in the tree is that 100% of the times it is Monday and I have the cash to pay for the steak I will pay for it and 100% of the time I don’t quite have enough in my pocket I will have to find some other option. That’s how we start each branch of the tree, starting with the first branch.
How Do We Use Math To Solve This Problem?
There’s a couple ways to go about this. For today, I’d like to discuss gini (pronounced the same as Ginny Weasley from Harry Potter). Gini is a measure of something called impurity. Most of the time, with the exception of my Monday / steak example, we don’t have completely decisive features. Usually there is variance within each feature. Impurity is the amount of confusion or lack of clarity in the decisiveness of a feature. So if we have a feature that has around 50% of the occurrences resulting in outcome 1 and 50% resulting in outcome 2, we have not learned anything exciting. By leveraging the gini statistic, we can understand which of our features is least impure and start the tree with that feature and then continue the tree by having the next branch be whatever is least impure in reference to the previous branch. So here is the equation we have all been waiting for:
Here’s a quick example, and then I’ll get back to the equation (I apologize for the rotation):
In the example above, I only compare the target feature to whether it’s rainy or not. There is no conditional probability here on things like time of day or day of week. This implies that we are at (or deciding) the top of the tree and seeing if raininess is as strong a predictive feature as other ones. We see that if we assume it is rainy, our gini impurity, as measured by one minus the probability of yes and the probability of no (both squared), sits around 0.32. If it is not a rainy day, the gini impurity is a bit higher, meaning we don’t have as much clarity as to whether or not I will go to the gym. In the weighted average result of 0.38, we see that this number is close to 0.4 than 0.32 because most days are not rainy days. In my opinion, using this data generated on the spot for demonstration purposes, the gini impurity for raniness is quite high and therefore would not sit at the top of the tree. It would be a lower branch. This concept is not exclusive to the binary choice, however it presents itself differently in other case. Say we want to know if I go to the gym based on how much free time I have in my day and my options include a range of numbers such as 60 minutes, 75 minutes, 85 minutes, and other values. To decide how we split the tree, we create “cutoff” points (corresponding to each value – so we create a cutoff at over 67.5 minutes and below 67.5 minutes followed by testing the next cutoff at over 80 minutes and below 80 minutes) to find the “cutoff” point with the least impurity. In other words, if we assume that the best way to measure whether I go or not is by deciding if I have more than 80 minutes free or less than 80 minutes free, than the tree goes on to ask if I have more than 80 minutes or less than 80 minutes. I also think this means that the cutoff point can change in different parts of the tree. For example, the 80 minute concept may be important on rainy days but I may go to the gym even with less free time on sunny days. Note that the cutoff always represents a binary direction forward. Basically we keep following the decision tree down using gini as a guide until we get to the last feature. At that point we just use the majority to decide.
Conclusion
Decision trees are actually not that complex, they can just take a long time when you have a lot of data. This is great to know and quite comforting considering how fundamental they implicitly are to everyday life. If you’re ever trying to understand the algorithm, explain it in an interview, or make your own decision tree (for whatever reason…), I hope this has been a good guide.
Effectively Predicting the Outcome of a Shark Tank Pitch
yikes
Introduction
Thank you for visiting my blog today!
Recently, during my quarantine, I have found myself watching a lot of Shark Tank. In case you are living under a rock, Shark Tank is a thrilling (and often parodied) reality TV show (currently on CNBC) where hopeful entrepreneurs come into the “tank” and face-off against five “sharks.” The sharks are successful entrepreneurs who are basically de-facto venture capitalists looking to invest in the hopeful entrepreneurs mentioned above. It’s called “Shark Tank” and not something a bit less intimidating because things get intense in the tank. Entrepreneurs are “put through the ringer” and forced to prove themselves worthy of investment in every way imaginable while standing up to strong scrutiny from the sharks. Entrepreneurs need to demonstrate that they have a good product, understand how to run a business, understand the economic climate, are a pleasant person to work with, are trustworthy, and the list goes on and on. Plus, contestants are on TV for the whole world to watch and that just adds to the pressure to impress. If one succeeds, and manages to agree on a deal with a shark (usually a shark pays a dollar amount for a percentage equity in an entrepreneur’s business), the rewards are usually quite spectacular and entrepreneurs tend to get quite rich. I like to think of the show, even though I watch it so much, as a nice way for regular folks like myself to feel intelligent and business-savvy for a hot second. Plus, it’s always hilarious to see some of the less traditional business pitches (The “Ionic Ear” did not age well: https://www.youtube.com/watch?v=FTttlgdvouY). That said, I set out to look at the first couple seasons of Shark Tank from a data scientist / statistician’s perspective and build a model to understand whether or not an entrepreneur would succeed or fail during their moment in the tank. Let’s dive in!
Data Collection
To start off, my data comes from kaggle.com and can be found at (https://www.kaggle.com/rahulsathyajit/shark-tank-pitches). My goal was to predict the target feature “deal” which was either a zero representing a failure to agree on a deal or a 1 for a successful pitch. My predictive features were (by name): description, episode, category, entrepreneurs, location, website, askedFor, exchangeForStake, valuation, season, shark1, shark2, shark3, shark4, shark5, episode-season, and Multiple Entrepreneurs. Entrepreneurs meant the name of the person pitching a new business, asked for means how much money was requested, exchange for stake represents percent ownership offered by the entrepreneur, valuation was the implied valuation of the company, shark1-5 is just who was present (so shark1 could be Mark Cuban or Kevin Harrington, for example), and multiple entrepreneurs was a binary of whether or not there were multiple business owners beforehand. I think those are the only features that require explanation. I used dummy variables to identify which sharks were present in each pitch (this is different from the shark1 variable as now it says Mark Cuban, for example, as a column name with either a zero or one assigned depending on whether or not he was on for that episode) and also used dummy variables to identify the category of each pitch. I also created some custom features. Thus, before removing highly correlated features, my features now also included the dummy variables described above, website converted to a true-false variable depending on whether or not one existed, website length, a binned perspective on the amount asked for and valuation, and a numeric label identifying which unique group of sharks sat for each pitch.
EDA (Exploratory Data Analysis)
The main goal of my blog here was to see how strong of a model I could build. However, an exciting part of any data-oriented problem is actually looking at the data and getting comfortable with what it looks like both numerically and visually. This allows one to easily share fun observations, but also provides context on how to think about some features throughout the project. Here are some of my findings:
Here is the distribution of the most common pitches (using top 15):
Here is the likelihood of getting a deal by category with an added filter for how much of a stake was asked for:
Here are some other relationships with the likelihood of getting a deal:
Here are some basic trends from season 1 to season 6:
Here is the frequency of each shark group:
Here are some other trends over the seasons. Keep in mind that the index starts at zero but that relates to season 1:
Here is the average stake offered by leading categories:
Here comes an interesting breakdown of what happens when there is and is not a guest shark like Richard Branson:
Here is a breakdown of where the most common entrepreneurs come from:
In terms of the most likely shark group for people from different locations:
I also made some visuals of the amount of appearances of each unique category by each of the 50 states. We obviously won’t go through every state. Here are a couple, though:
Here is the average valuation by category:
Here is a distribution of pitches to the different shark groups (please ignore the weird formatting):
Here come some various visuals related to location:
Here come some various visuals related to shark group
This concludes my EDA for now.
Modeling
After doing some basic data cleaning and feature engineering, it’s time to see if I can actually build a good model.
First Model
For my first model, I used dummy variables for the “category” feature and information on sharks. Due to the problem of having different instances of the category feature, I split my data into a training and test set after pre-processing the data. I mixed and matched a couple of scaling methods and machine learning classification models before landing on standard scaling and logistic regression. Here was my first set of results:
In terms of an ROC/AUC visual:
64% accuracy on a show where anything can happen is a great start. Here were my coefficients in terms of a visual:
Let’s talk about these results. It seems like having Barbara Corcoran as a shark is the most likely indicator of a potential deal. That doesn’t mean Barbara makes the most deals. Rather, it means that you are likely to get a deal from someone if Barbara happens to be present. I really like Kevin because he always makes a ridiculous offer centered around royalties. His coefficient sits around zero. Effectively, if Kevin is there, we have no idea whether or not there will be a deal. He contributes nothing to my model. (He may as well be dead to me). Location seems to be an important decider. I interpret this to mean that some locations appear very infrequently and just happened to strike a deal. Furniture, music, and home improvement seem to be the most successful types of pitches. I’ll let you take a look for yourself to gain further insights.
Second Model
For my second model, I leveraged target encoding for all categorical data. This allowed me to split up my data before any preprocessing. I also spent time writing a complex backend helper module to automate my notebook. Here’s what my notebook looked like after all that work:
That was fast. Let’s see how well this new model performed given the new method used in feature engineering:
There is clearly a sharp and meaningful improvement present. That said, by using target encoding, I can no longer see the effects of individual categories pitched or sharks present. Here were my new coefficients:
These are a lot less coefficients than in my previous model due to the dummy variable problem, but this led to higher scores. This second model really shocked me. 86% accuracy for predicting the success of a shark tank pitch really surprised me given all the variability present in the show.
Conclusion
I was really glad that my first model was 64% accurate given what the show is like and all the variability involved. I came away with some insightful coefficients to understand what drove predictions. By sacrificing some detailed information I kept with dummy variables, I was able to encode categorical data in a different way which led to an even more accurate model. I’m excited to continue this project and add more data from more recent episodes to continue to build a more meaningful model.
Thanks for reading and I hope this was fun for any Shark Tank fans out there.
Today, I’m going to be doing the third part of my series in linear regression. I originally intended to end on part 3, but I have considered continuing with further blogs. We’ll see what happens. In my first blog, I introduced the concepts and foundations of linear regression. In my second blog, I talked about one topic often correlated to linear regression known as gradient descent. In many ways, this third blog represents the most exciting blog in the series, but also the shortest and easiest to compose blog. Why? The answer is that I hope to empower and inspire anyone with even moderate interest in python to perform meaningful analysis using linear regression. We’ll soon see that once you have the right framework, it is a pretty simple process. Now, keep in mind that the regression I will display is about as easy and simple as it gets. The data I chose was clean and based on what I had seen online, was not that complex. So pay attention to the parts that allow you to perform regression and not the parts that relate to data cleaning.
Data Collection
My data comes from kaggle.com and can be found at (https://www.kaggle.com/greenwing1985/housepricing). The data (which I think is not from a real world data set) talks about house pricing with features including (by name): area, garage, fire place, baths, white marble, black marble, Indian marble, floors, city, solar, electric, fiber, glass doors, swimming pool, and garden. The target feature was price.
Before I give you screenshots with data, I’d like to provide all the necessary imports for python (plus some extra ones I didn’t use but are usually quite important).
Here’s a look at the actual data:
Here is a list of how many null values occur in each variable as well as each variable’s data type
We see three key observations here. One is that we have 500000 rows of each value. Two is that we have no null values. Finally, three is that they are all represented using integers.
One last observation: the target class seems to be normally distributed to some degree.
Linear Regression Assumptions
Linearity
Conveniently, most of our data consists of discrete features with values consisting of whole numbers between 1 and 5. That makes life somewhat easier. The only feature to really test was area. Here goes:
This is not the most beautiful graph. I have however, concluded that it satisfies linearity and have confirmed this conclusion with others who look at this data.
Multicollinearity
Do features correlate highly to each other?
Based on a filter of 70%, which is common, it seems like the features have no meaningful correlation with each other.
Normal Distribution of Residuals
First, of all the average of residuals is around zero, so that’s a good start. I realize that the following graph is not the most convincing visual but I was able to confirm that this assumption is satisfied.
Homoscedasticity
I’ll be very honest, this was a bit of a mess. In the imports above I show an import for the Breusch-Pagan test (https://en.wikipedia.org/wiki/Breusch%E2%80%93Pagan_test). I’ll save you the visuals, as I didn’t find them convincing. However, my conclusions appeared to be right as they were confirmed in the kaggle community. So, in the end there was homoscedasticity present.
Conclusion
We have everything we need to conduct linear regression.
There are two primary methods of linear regression. One is by using statsmodels and the other one is by using sklearn. I don’t know how to split data in statsmodels and later evaluate on other data, in a quick way, at least within statsmodels. That said, statsmodels gives a more comprehensive summary as we are about to see. So there is a tradeoff between which package you choose. You’ll soon see what I mean in more detail. In three lines of code, I am going to create a regression model, fit the regression, and check results. Let’s see:
I won’t bore you with details that much. Just notice how much we were able to extract and understand in a simple three lines of code. If you’re confused, here is what you should know: R-squared is a scale of 0 to 1 representing how good your model is. 1 is the best score. Also the coef column, which we will look at later, represents coefficients. (The coefficients here make me really skeptical that this is real data. Although, that view comes from a Chicagoan’s perspective. I’m sure the dynamic changes as you move around geographically, though).
Sklearn Method
This is the method I use most often. In the code below, I create, train, and validate a regression model.
In terms of coefficients:
Even though regression can get fairly complex, running a regression is pretty simple once the data is ready. It’s also a nice data set as my R-squared is basically 100%. That’s obviously not realistic, but that’s not the point of this blog.
Conclusion
While linear regression is a powerful and complex analytical process, it turns out that running regression in the context of python, or other coding language, I would imagine, is actually quite simple. Checking assumptions is rather easy and so is creating, training, and evaluating models. That said, regression can get more difficult, but for less complex questions and data sets, it’s a fairly straight-forward process. So even if you have no idea how regression really works, you can fake it to some degree. In all seriousness, though, you can draw meaningful insights, in some cases, with a limited background.
Building an Understanding of Gradient Descent Using Computer Programming
Introduction
Thank you for visiting my blog.
Today’s blog is the second blog in a series I am doing on linear regression. If you are reading this blog, I hope you have a fundamental understanding of what linear regression is and what a linear regression model looks like. If you don’t already know about linear regression, you may want to read this blog: https://data8.science.blog/2020/08/12/linear-regression-part-1/ I wrote and come back later. In the blog referenced above, I talk at a high level about optimizing for parameters like slope and intercept. Well, we are going to talk about how machines minimize error in predictive models. We are going to introduce the idea of a cost function soon. Even though we will be discussing cost functions in the context of linear regression, you will probably realize that this is not the only application. That said, the title of this blog shouldn’t confuse anyone and all should understand that gradient descent is more of an overarching subject for many machine learning problems.
The Cost Function
The first idea that needs to be introduced, as we begin to discuss gradient descent, is the cost function. As you may recall, we wrote out a pretty simple calculus formula that found the optimal slope and intercept for the 2D model in the last blog. If you didn’t read last blog, that’s fine. The main idea is that we started with an error function, or MSE. We then took partial derivatives of that function and applied optimization techniques to search for a minimum. What I didn’t tell you in my blog, and people who didn’t read my blog may or may not know is that there is in fact a name for the function that takes a partial derivate in an error function. We call it the cost function. Here is a common representation of the cost function (for 2-dimensional case):
This function should be familiar. This is basically just the sum of model error in linear regression. Model error is what we try to minimize in EVERY machine learning model, so I hope you see why gradient descent is not unique for linear algebra.
What is a Gradient?
Simply put, a gradient is the slope of a curve, or derivative, at any point on a plane with regards to one variable (in a multivariate function). Since the function being minimized is the loss function, we follow the gradient down (hence the name gradient descent) until it approaches or hits zero (for each variable) in order to have minimal error. In gradient descent, we start by taking big steps and slow down as we get closer to that point of minimal error. That’s what gradient descent is; slowly descending down a curve or graph to the lowest point, which represents minimal error, and finding the parameters that correspond to that low point. Here’s a good visualization for gradient descent (for one variable).
The next equation is one I found online that illustrates how we use the graph above in practice:
The above two visual may seem confusing, so let’s work backwards. W t+1 corresponds to our next predicted value for optimal coefficient value. W t was our previous assumption for optimal coefficient value. The term on the right looks a bit funky, but it’s pretty simple actually. The alpha corresponds to the learning rate and the quotient is the gradient. The learning rate is essentially a parameter that tells us how quickly we move. If it is low, models can be computationally expensive, but if it is high, it may not hit the best concluding point. At this point, we can revisit the gif. The gif shows the movement in error as we iteratively update W t into W t+1.
At this point, I have sort-of discussed the gradient itself and danced around the topic. Now, let’s address it directly using visuals. Now keep in mind, gradients are partial derivatives for variables in the cost function that enable us to search for a minimum value. Also, for the sake of keeping things simple, I will express gradients using the two-dimensional model. Hopefully, the following visual shows a clear progression from the cost function.
In case the above confuses you, I would not focus on the left side of either the top or bottom equation. Focus on the right side. These formulas should look familiar as they were part of my handwritten notes in my initial linear regression blog. These functions represent the gradients used for slope (m) and intercept (b) in gradient descent.
Let’s review: we want to minimize error and use the derivative of the error function to help that process. Again, this is gradient descent in a simple form:
I’d like to now go through some code in the next steps.
Gradient Descent Code
We’ll start with a simple model:
Next, we have our error:
Here we have a single step in gradient descent:
Finally, here is the full gradient descent:
Bonus Content!
I also created an interactive function for gradient descent and will provide a demo. You can copy my notes from this notebook with your own x and y values to run an interactive gradient descent as well.
Gradient descent is a simple concept that can be incredibly powerful in many situations. It works well with linear regression, and that’s why I decided to discuss it here. I am told that often times, in the real world, using a simple sklearn or stastsmodels model is not good enough. If it were that easy, I imagine the demand for data scientists with advanced statistical skills would be lower. Instead, I have been told, that custom cost functions have to be carefully though out and gradient descent can be used to optimize those models. I also did my first blog video for today’s blog and hope it went over well. I have one more blog in this series where I go through regression using python.
Acquiring a baseline understanding of the ideas and concepts that drive linear regression.
Introduction
Thanks for visiting my blog!
Today, I’d like to do my first part in a multi-part blog series discussing linear regression. In part 1, I will go through the basic ideas and concepts that describe what a linear regression is at its core, how you create one and optimize its effectiveness, what it may be used for, and why it matters. In part 2, I will go through a concept called gradient descent and show how I would build my own gradient descent, by hand, using python. In part 3, I will go through the basic process of running linear regression using scikit-learn in python.
This may not be the most formal or by-the-book guide, but the goal here is to build a solid foundation and understanding of how to perform a linear regression and what the main concepts are.
Motivating Question
Say we have the following (first 15 of 250) rows of data (it was randomly generated and does not intentionally represent any real world scenario or data):
Graphically, here is what these 250 rows sort of look like:
We want to impose a line that will guide our future predictions:
The above graph displays the relationship between input and output using a line, called the regression line, that has a particular slope as well as a starting point, the intercept, which is an initial value added to each output and in this case sits around 35. Now, if we see the value 9 in the future as an input, we can assume the output would lie somewhere around 75. Note that this closely resembles our actual data where we see the (9.17, 77.89) pairing. Moving on, this corresponds on our regression line to an intercept of 35 + 9 scaled by the slope which might be around 40/9, or 4.5. Or in basic algebra y=mx+b: 75 = 4.5*9 +35. That’s all regression is! Basic algebra using scatter plots. That was really easy I think. Now keep in mind that we only have one input here. In a more conventional regression, we have many variables and each one has its own “slope,” or in other words, effect on output. We need to use more complex math to allow for the ability to measure the effect of every input. For this blog we will consider the single input case, though. It will allow us to have a discussion about how linear regression works as a concept and also give us a starting point to think about how we might change our approach, or really adjust our approach, as we move into data that is contextualized or described in 3 or more dimensions. Basic case: find effect of height on wingspan. Less basic case: find effect of height, weight, country, and birth year on life expectancy. Case 2 is far more complex but we will be able to address it by the end of the blog!
Assumptions
Not every data set is suited for linear regression; there are rules, or assumptions, that must be in place.
Assumption 1: Linearity. This one is probably one you already expected, just didn’t know you expected it. We can only use LINEAR regression if the relationship shown in the data is, you know, linear. If the trend in the scatter plot looks like it needs to be described using some higher degree polynomial or other type of non-linear function like a square root or logarithm than you probably can’t use linear regression. That being said, linear regression is only one method of supervised machine learning for predicting continuous outputs. There are many more options. Let’s use some visuals:
Now, you may be wondering the following: this is pretty simple in the 2D case, but is it easy to test this assumption in higher dimensions? The answer is yes.
Assumption 2: Low Correlation Between Predictive Features. Our 2D case is an exception in a sense. We are only discussing the simple y=mx+b case here and the particular assumption listed above is more suited to multiple linear regression. Multiple linear regression is more like y= m1x1+m2x2+…+b. Basically, it has multiple independent variables. Say you are trying to predict how many points a game a player might score on any given night in the NBA and your features include things like height, weight, position, all-star games made, and some stats about how their vertical leap or running speed. Now, let’s say you also have the features that say a player’s age and what year they were drafted. Age and draft year are inherently correlated. We would probably not want to use both draft year and age. We know what this idea of reducing correlation means by using that example, but why is it important to reduce correlation? Well, one topic to understand is coefficients. Coefficients are basically the conclusion of a regression. They tell us how important each feature is and what its impact is on output. In the y=mx+b equation, m is the coefficient of x, the independent variable, and basically tells us how the dependent variable responds to each x value. So if you have an m value of 2 it means that the output variable increases by twice the value of the input variable. Say you are trying to predict NBA salary based on points per game. Well, let’s use two data points. Stephen Curry makes about $1.5M per point averaged and LeBron James makes about $1.4M per point averaged. Now, these players are outliers, but we get a basic idea that star players make like $1.45M per point averaged. That’s the point of regression; finding causal relationship between input and output. We lose the ability to find the impact of unique features on output when there are highly correlated features as they often move together and represent being tied together in certain ways.
Assumption 3: Homoscedasticity. Basically, what homoscedasticity means is that there is no “trend” in your data. What do I mean by “trend?”. By this, I mean that if you take a look at all the error values in your data (say your first value is 86 and you predict 87 and the second prediction is 88 but the true value is 89, then your first two errors are valued at 1 and -1), whether positive or negative, and plot it around the line y=0 representing no error, then we would not see a pattern in the resulting scatter plot and we might assume that the points around that line (y=0) would look to be rather random and most importantly, have constant variance. This plot we just described, that has a baseline of y=0 and error terms around it is called a residual plot. Let me give you the visual you have been waiting for in terms of residual plots. Also note that we didn’t discuss heteroscedasticity – but it’s basically the opposite of homoscedasticity, I think that’s quite obvious.
Assumption 4: Normality. This means that distribution of the error of the points that fall above and below the line is normally distributed. Note that this refers to the distribution of the value of the error (also called residuals – the value of which is calculated by subtracting the true value from the estimated value at every single value in the scatter plot measured against the closest value in the regression line), not the distribution of the y values. Here is a basic normal distribution. Hopefully, the largest portion of the value of the residuals fall around a center point (not necessarily at the value zero, it’s just an indicator of zero standard deviations from the mean – that’s what the x-axis is) and the amount of smaller and larger residuals appear in smaller quantities.
This next graph shows where the residuals should fall to have normality present, with E(y) representing the expected value (Credit to Brandon Foltz from YouTube for this visual).
Both graphs work, but at different scales.
Fitting A Line
Ok, so now that we have our key assumptions in place, we can start searching for the line that best fits the data. The particular method I’d like to discuss here is called ordinary least squares, or OLS. OLS sums up the difference between every predicted point and every true value (once again, each of those values is called a “residual,” which represents error) and squares this difference, adds it to the sum of residuals, and divides that final sum over the total number of data points. We call this metric MSE; mean squared error. So it’s basically finding the average error and looking for the model with lowest average error. To do this, we optimize the slope and intercept for the regression line so that each point is as close as possible to the true value as judged by MSE. As you can see by the GIF below, we start with a simple assumptions and move quickly toward the best line but slow down as we get closer and closer. (Also notice that we almost always start with assumption of a slope of zero. This is basically testing the hypothesis that input has no effect on output. In higher dimension, we always start with the simple assumption that every feature in our model has no effect on output and move closer to its true value carefully. This idea relates to a concept called gradient descent which will be discussed in the next blog in this series).
Now, one word you may notice that I used in the paragraph above is “optimize.” In case, you don’t already see where I’m going with this, we are going to need calculus. The following equation represents error and the metric we want to minimize as discussed above.
That E looking letter is the Greek letter Sigma which represents a sum. The plain y is the true value (one exists for every value of x), and the y with a ^ (called y-hat) on top represents the predicted value. We basically square these terms so that we can look at error in absolute value terms. I would add a subscript of a little “n” next to every y and y-hat value to indicate that there are like a lot of these observations. Now keep in mind, this is going to be somewhat annoying to derive, but once we know what our metrics are we can use the formulas going forward. To start, we are going to expand the equation for a regression line and write it in a more formal way:
So, now we can look at MSE as follows:
This is the equation we need to optimize. To do this we will take the derivative with respect to all of our two unknown constants and set those results equal to zero. I’m going to do this by hand and add some pictures as typing it would take a while.
Step 1: Write down what needs to be written down; the basic formula, a formula where I rename the variables, and the partial derivatives for each unknown (If you don’t know what a partial derivative is that’s okay, it just tells us the equation we need to set equal to zero, because at zero we have a minimum in the value we are investigating, which is error in this case. Both error for slope value and error for intercept value. Those funky swirls that with the letters F on top and A or B below represent those equations).
Conclusion: We have everything we need to go forward.
Step 2: Solve one equation. We have two variables, and in case you don’t know how this works, we will therefore need two equations. Let’s start with the simpler equation.
Conclusion: A, or our intercept term equals the average of y, as indicated by the bar, minus the slope scaled by the average of x (keep in mind this is an average due to the 1/n, or “1 over N”, term not included. Also remember that for the end of the next calculation).
Step 3: Solve the other equation, using substitution (apologies for the rotation).
Conclusion: After a lot of math we got our answer. You may notice I took an extra step at the end and added a little box around that extra step. The reason for this is because that equation (hopefully, at the very least, you have encountered the denominator before) in that box is equal to the covariance between x and y divided by the variance of x. Those equations are fairly simple but are nevertheless beyond the scope of this blog. Let’s review how we calculate slope.
That was annoying, but we have our two metrics! Keep in mind that this process can be extended with increased complexity to higher dimensions. However, for those problems, which will be discussed in part 3, we are just going to use python and all its associated magic.
Evaluating Your Model
Now that we know how to build a basic slope-intercept model, how can we evaluate whether or not it is effective? Keep in mind that magnitude of the data you model may change which means that looking at MSE and only MSE will not be enough. We need the MSE to know what to optimize for low error, but we are going to need a bit more than that to evaluate a regression. Let’s now discuss R-Squared. R-Squared is a 0-1 or 0%-100% scale of how much variance is captured by our model. That sounds a bit weird and that’s because it’s a rather technical definition. R-Squared really answers the following question: How good is your model? Well, 0% means your model is the worst thing since the New York Yankees were introduced. A score in the 70%-90% range is more desirable. (100%, which you are no doubt wondering why I didn’t pick, means you probably overfit on training data and made a bad model). This is all nice, but how do we calculate this metric?
One minus the sum of each prediction’s deviation from the true value divided each true value’s deviation from the mean (with both the numerator and denominator squared to account for that absolute value issue discussed earlier). You can probably guess the SS-RES label alludes to the concept of residuals and the sum of squares from residuals; true values minus the predicted values squared. The bottom refers to total sum of squares; a metric for deviation from the mean. In other words, (one minus) the amount of error in our model versus the amount of total error. There is also metric you may have heard of called “Adjusted R-Squared.” The idea behind this is to penalize excessively complex models. We are looking at a simple case here with only one true input, so it doesn’t really apply. Just know it exists for other models. Keep in mind that R-Squared doesn’t always measure how effective you in particular were at creating a model. It could be that it’s just a hard model to construct or one that will never work well independent of who creates the model. (Now you may be wondering how to people can have a different regression model. It’s a simple question but I think it’s important. The real difference between two models can present themselves in many ways. A key one, for example, is how one decides to pre-process their data. One person may remove outliers to different degrees than others and that can make a huge difference. Nevertheless, even though models are not all created equally, some have a lower celling or higher floor than others for R-Squared values).
Conclusion
I think if there’s one point to take home from this blog, it’s that linear regression is a relatively easy concept to wrap your head around. It’s very encouraging that such a basic concept is also highly valued as a skill to have as linear regression can be used to model many real world scenarios and has so many applications (like modeling professional athlete salaries or forecasting sales). Linear regression is also incredibly powerful because it can measure the effect of multiple inputs and their isolated impact on a singular output.
Let’s review. In this blog, we started by introducing a scenario to motivate interest in linear regression, discussed when it would be appropriate to conduct linear regression, broke down a regression equation into its core components, derived a formula for those components, and introduced metrics to evaluate the effectiveness of our model.
From my perspective, this blog presented me with a great opportunity to brush up on my skills in linear regression. I conduct linear regression models quite often (and we’ll see how those work in part 3) but don’t always spend a lot of time thinking about the underlying math and concepts, so writing this blog was quite enjoyable. I hope you enjoyed reading part 1 of this blog and will stick around for the next segment in this series. The next concept (in part 2, that is) I will discuss is a lesser known concept (compared to linear regression) called gradient descent. Stay tuned!
Understanding the Elements and Metrics Derived from Confusion Matrices when Evaluating Model Performance in Machine Learning Classification
Introduction
Thanks for visiting my blog.
I hope my readers get the joke displayed above. If they don’t and they’re also millennials, they missed out on some great childhood fun.
What are confusion matrices? Why do they matter? Well… a confusion matrix, in a relatively simple case, shows the distribution of predictions compared to real values in a machine learning classification model. Classification can theoretically have many target classes, but for this blog we are going to keep it simple and discuss prediction of a binary variable. In today’s blog, I’m going to explain the whole concept and how to understand confusion matrices on sight as well as the metrics you can pick up by looking at them.
Plan
Provide Visual
Accuracy
Recall
Precision
F-1
AUC-ROC Curve
Quick note: there are more metrics that derive from confusion matrices beyond what’s listed above. However, these are the most important and relevant metrics generally discussed.
Visualization
I have three visuals. The first one displays the actual logic behind confusion matrices while the second displays an example and the third displays a heat-map. Often, using a heat-map can be easier to decode and also easier to share with others. I’d like to also note that confusion matrix layouts can change. I would not get caught up on one particular format and just understand that rows correspond to predicted values columns correspond to actual values. The way the numbers within each of those are arranged is variable.
Basic explanation.
Now you will always have numbers in those quadrants and generally hope that the top left and bottom right have the highest values.
Heat-map.
As we can see above, knowing that red corresponds to higher values quickly gives us the reflection that our model worked well. In “error” locations, we have a strong blue color, while in “correct” areas we see a lot of red.
Before I get into the metrics, I need to quickly explain what TP, FP, TN, and FN mean. This won’t take long. TP is a true positive, like someone correctly being predicted to have a disease. TN is true negative, like someone correctly predicted to not have a disease. FN is a false negative, like some who was predicted to not have a disease but actually does. FP is a false positive, like some predicted to have a disease but actually doesn’t. This is a preview of some metrics to be discussed, but for certain models the importance of FN, FP, TN, and TP is variable and some may matter more than others.
Quick note: When I think of the words “accuracy” and “precision,” the first thing that comes to mind is what I learned back in Probability Theory; accuracy means unbiasedness and precision means minimal variance. I’ll talk about bias and variance in a later blog. For this blog, I’m not going to place too much focus on those particular definitions.
Accuracy
Accuracy is probably the most basic and simple idea. Accuracy is determined by summing true positive and true negative results over both the true positive and true negative predictions but also false positive and false negative predictions. In other words, of every single prediction you made, how many of them were right. So this means we want to know that if it was a negative how many times did you predict correctly and vice-versa for a positive. That being the case, when does accuracy become the most important metric to your model and when does accuracy fall short of being a strong or important metric? Let’s start with the cases where accuracy falls short. If you have a large class imbalance such as 10 billion rows in class 0 and 1 row in class 1, than you don’t necessarily have a strong model if it accurately predicts most of the majority class and predicts the minority class accurately the one time it occurs (or doesn’t predict the minority class correctly for that matter). Accuracy works well and tells a good story with more balanced data. However, as discussed above, it can lose meaning with a target class imbalance.
Here is a heat map of a high accuracy model.
Recall
Recall can most easily be described as true positives divided by true positives and false negatives. This corresponds to the number of positives correctly identified when in fact the case was positive. A false negative means an unidentified positive. False positives and true negatives are not meant to be positives (in a perfect model) so are not included. So if you are trying to identify if someone has a disease or not, having high recall would be good for you model since it means that when the disease is present, you identify it well. You could still have low accuracy or precision in this model if you don’t predict the non-disease class well. In other words if you predict every row as having the disease than your recall will be high since you will have correctly predicted every occurrence where the disease was actually present. Unfortunately, however, the impact of having a correct prediction will be diminished and mean a whole lot less. That leads us to precision.
Here is a heat map of a high recall model.
Precision
Precision can most easily be described as true positives divided by true positives and false positives. Unlike recall, which is a measure of actual positives discovered from the pool of all positives, precision is a measure of actual positives from predicted positives. So false negatives and true negatives don’t matter as they were not predicted to have been positive in the first place. A great way to think about precision is how meaningful a positive prediction is given the context of your model. Off the top of my head, I would assume that in a business where you owe some sort of service or compensation based on a predicted positive, having high precision would be important as you would not want to waste resources. I recently worked on an email spam detector. That is another example where high precision is ideal.
Here is a confusion matrix of a high precision model.
F-1 Score
The F-1 score is the harmonic mean of the precision and recall score which means its maximum value is the arithmetic mean of the two. (For more info on what a harmonic mean actually is – here is a Wikipedia page you may find helpful: https://en.wikipedia.org/wiki/Harmonic_mean). As you may have gathered or assumed from what’s written above, the F-1 score matters more in situations where accuracy may fall short.
Receiver Operating Curve (ROC) Curve
The basic description of this curve is that it measures how an increase in false positives to a model would correspond to increasing true positives which can evaluate your models ability to distinguish between classes. The horizontal axis values extend from 0% to 100% (or 0 to 1). The larger the area covered using the curve, the better your model is. You may be confused due to the lack of a visual. Let me show you what I mean:
Above, the “No Skill” label means that you’ll get 50% of classifications right at random (don’t get too caught up on that point). The high increase early in the x values on the corresponding vertical axis are a good sign that as more information is introduced into your model, than its true positive rate climbs quickly. It maxes out around 30% and then begins a moderate plateau. This is a good sign and shows a lot of area covered by this orange curve. The more area covered, the better.
Conclusion
Confusion matrices are often a key part of machine learning models and can help tell and important story about the effectiveness of your model. Since there are varying ways data can present itself, it is important to have different metrics that derive from these matrices to measure success for each situation. Conveniently, you can view confusion matrices with relative ease using heat maps.
Developing a process to predict which NBA teams and players will end up in the playoffs.
Introduction
Hello! Thanks for visiting my blog.
After spending the summer being reminded of just how incredible Michael Jordan was as a competitor and leader, the NBA is finally making a comeback and the [NBA] “bubble” is in full effect in Orlando. Therefore, I figured today would be the perfect time to discuss the NBA playoffs (I know the gif is for the NFL, but it is just too good to not use). Specifically, I’d like to answer the following question: if one were to look at some of the more basic NBA statistics recorded by an NBA player or team on a per-year basis, with what accuracy could you predict whether or not that player may find themselves in the NBA playoffs. Since the NBA has changed so much over time and each iteration has brought new and exciting skills to the forefront of strategies, I decided to stay up to date and look at the 2018-19 season for individual statistics (the three-point era). However, only having 30 data points to survey for team success will be insufficient to have a meaningful analysis. Therefore I expanded my survey to include data back to and including the 1979-80 NBA season (when Magic Johnson was still a rookie). I web-scraped basketball-reference.com to gather my data and it contains every basic stat and a couple advanced ones such as effective field goal percent (I don’t know how that is calculated but Wikipedia does: https://en.wikipedia.org/wiki/Effective_field_goal_percentage#:~:text=In%20basketball%2C%20effective%20field%20goal,only%20count%20for%20two%20points.) from every NBA season ever. As you go back in time, you do begin to lose data from some statistical categories that weren’t recorded yet. To give to examples here I would mention blocks which were not recorded until after the retirement of Bill Russell (widely considered the greatest defender to play the game) or three pointers made as three pointers were first introduced into the NBA in the late 1970s. So just to recap: if we look at fundamental statistics recorded by individuals or in a larger team setting – can we predict who will find themselves in the playoffs? Before we get started, I need to address the name of this blog. Gregg Popovich has successfully coached the San Antonio Spurs to the playoffs in every year since NBA legend Tim Duncan was a rookie. They are known to be a team that runs on good teamwork as opposed to outstanding individual play. This is not to say they have not had superstar efforts though. Devin Booker has been setting the league on fire, but his organization, the Phoenix Suns, have not positioned themselves to be playoff contenders. (McCaw just got lucky and was a role player for three straight NBA championships). This divide is the type of motivation that led me to pursue this project.
Plan
I would first like to mention that the main difficulty in this project was developing a good web-scraping function. However, I want to be transparent here and let you know that I worked hard developing that function a while back and now realized this would be a great use of that data. Anyhow, in my code I go through the basic data science process. In this blog, however, I think I will try to stick to the more exciting observations and conclusions I reached. (here’s a link to GitHub: https://github.com/ArielJosephCohen/postseason_prediction).
The Data
First things first, let’s discuss what my data looked like. In the 2018-19 NBA season, there were 530 total players to play in at least one NBA game. My features included: name, position, age, team, games played, games started, minutes played, field goals made, field goals attempted, field goal percent, three pointers made, three pointers attempted, three point percent, two pointers made, two pointers attempted, two point percent, effective field goal percent, free throws made, free throws attempted, free throw percent, offensive rebounds per game, defensive rebounds per game, total rebounds per game, assists per game, steals per game, blocks per game, points per game, turnovers per game, year (not really important but it only makes the most marginal difference in the team setting), college (or where they were before the NBA – many were null and were filled as unknown), draft selection (un-drafted players were assigned the statistical mean of 34 – which is later than I expected. Keep in mind the drat used to exceed 2 rounds). My survey of teams grouped all the numerical values (with the exception of year) by each team and every season using the statistical mean of all its players that season. In total, there were 1104 rows of data, some of which included teams like Seattle that no longer exist in their original form. My target feature was a binary 0 or 1 with 0 representing a failure to qualify for the playoffs and 1 representing a team that successfully earned a playoff spot.
One limitation of this model is that it accounts for trades or other methods of player movement by assigning a player’s entire season stats to the team he ended the season with, regardless of how many games were actually played on his final team. In addition, this model doesn’t account for more advanced metrics like screen assists or defensive rating. Another major limitation is something that I alluded to earlier: the NBA changes and so does strategy. This makes this more of a study or transcendent influences that remain constant over time as opposed to what worked well in the 2015-16 NBA season (on a team level that is). Also, my model focuses on recent data for the individual player model, not what individual statistics were of high value in different basketball eras. A great example of this is the so-called “death of the big man.” Basketball used to be focused on big and powerful centers and power forwards who would control and dominate the paint. Now, the game has moved much more outside, mid-range twos have been shunned as the worst shot in basketball and even centers must develop a shooting range to develop. Let me show you what I mean:
Now let’s look at “big guy”: 7-foot-tall Brook Lopez:
In a short period of time, he has drastically changed his primary shot selection. I have one more visual from my data to demonstrate this trend.
Exploratory Data Analysis
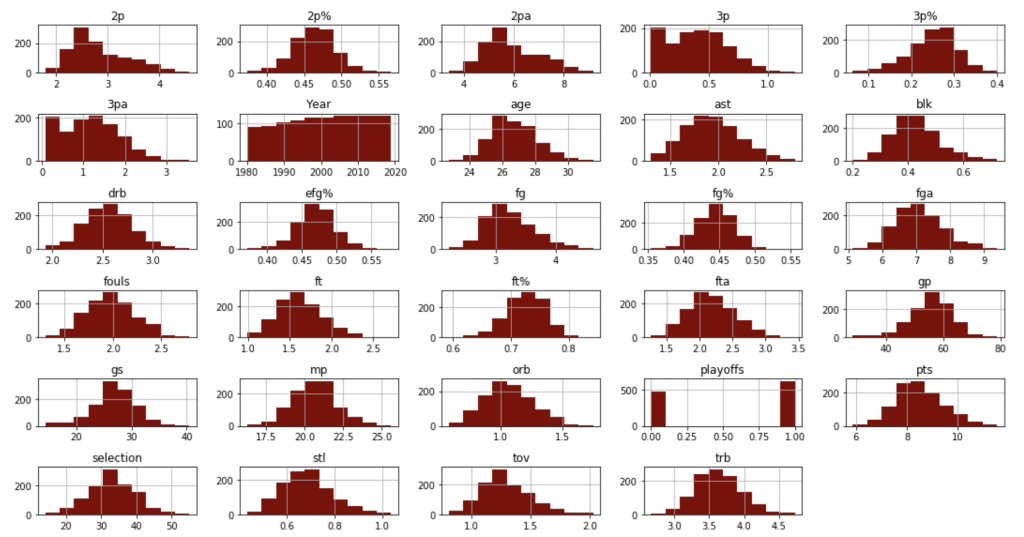
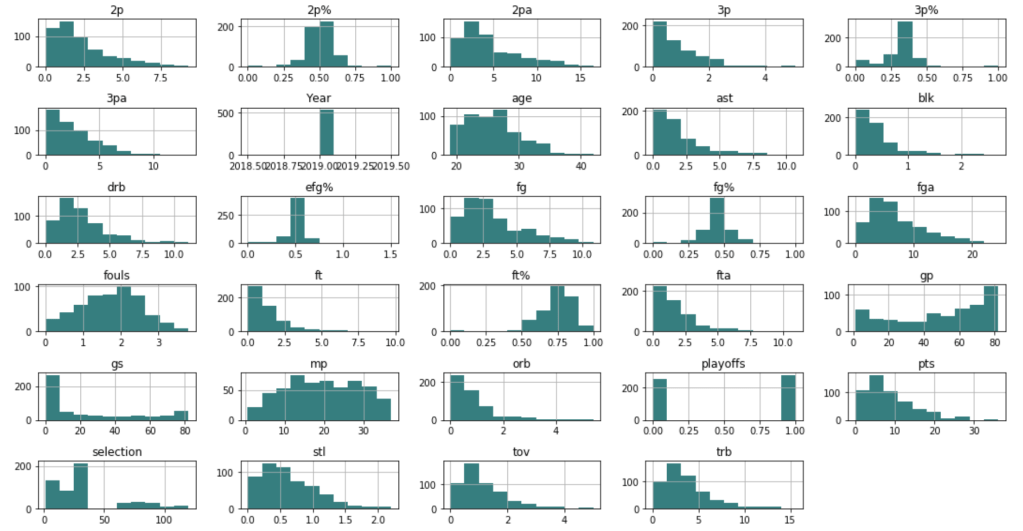
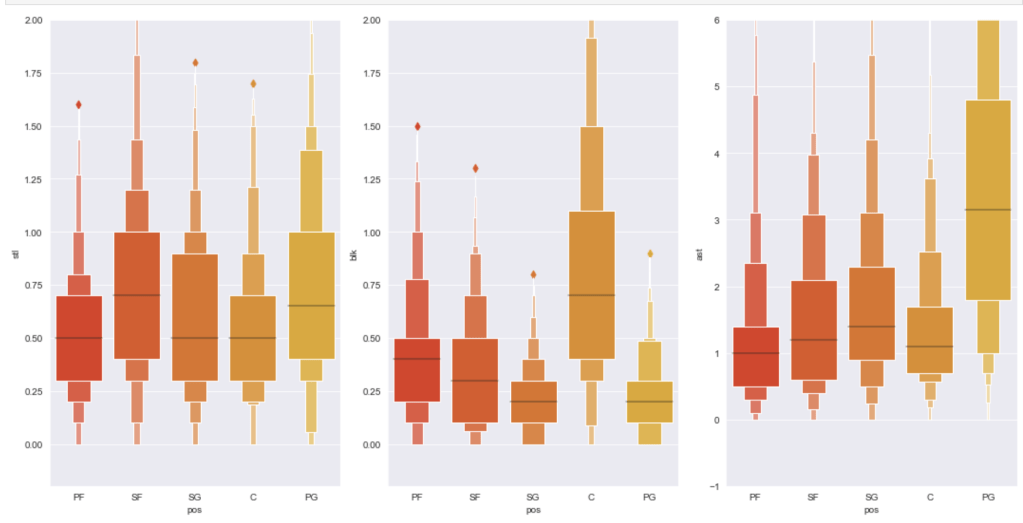
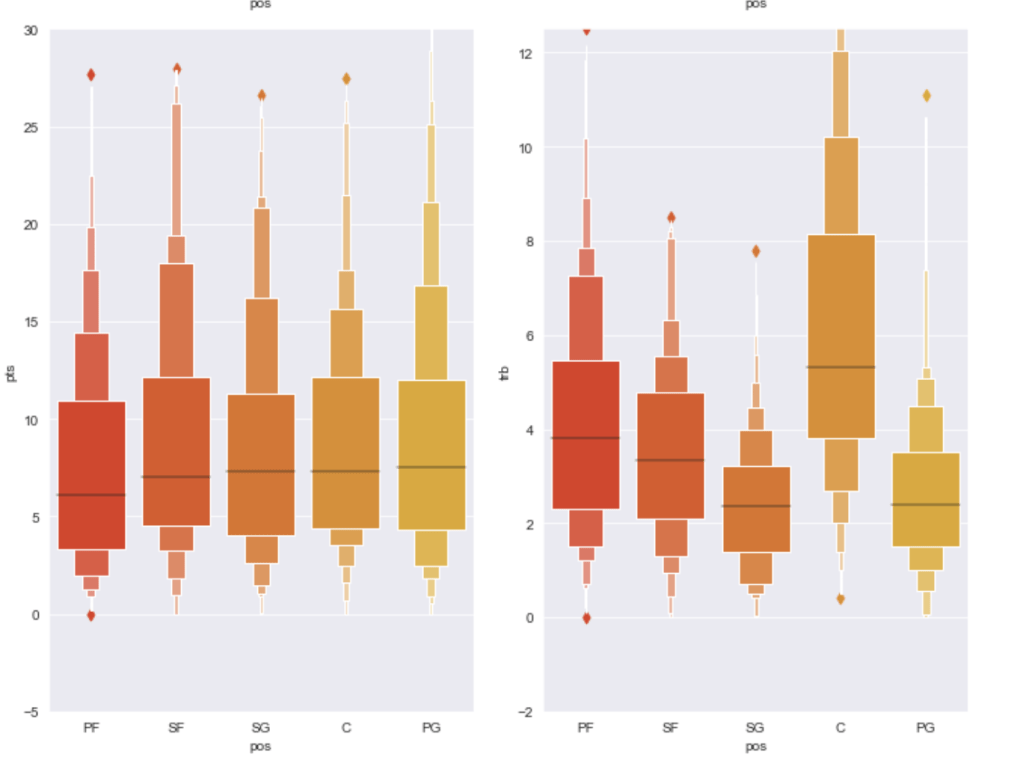
Before I get into what I learned from my model, I’d like to share some interesting observations from my data. I’ll start with two histograms groups:
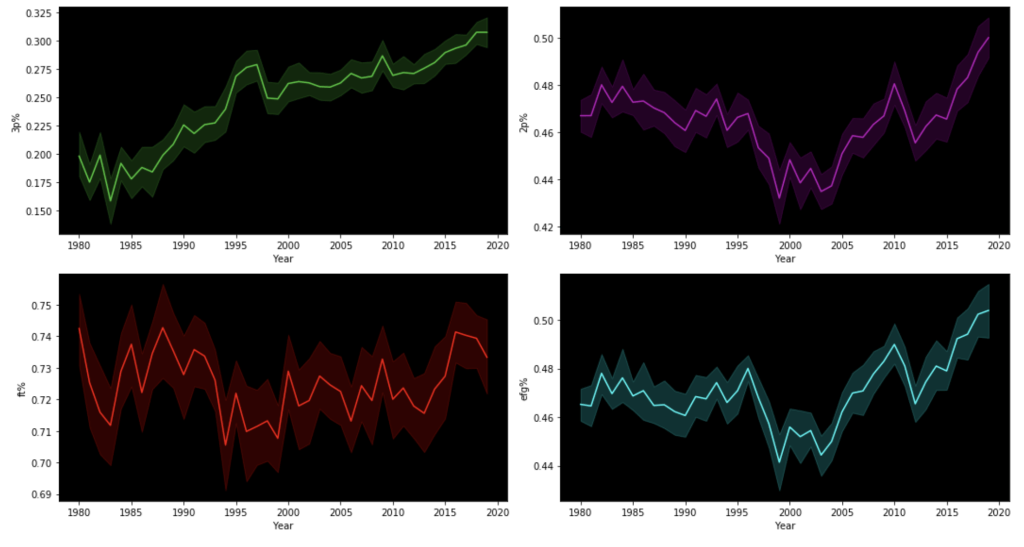
Team data histogramsIndividual data histogramsEvery year – playoff teams tend to have older playersTrends of various shooting percentages over time
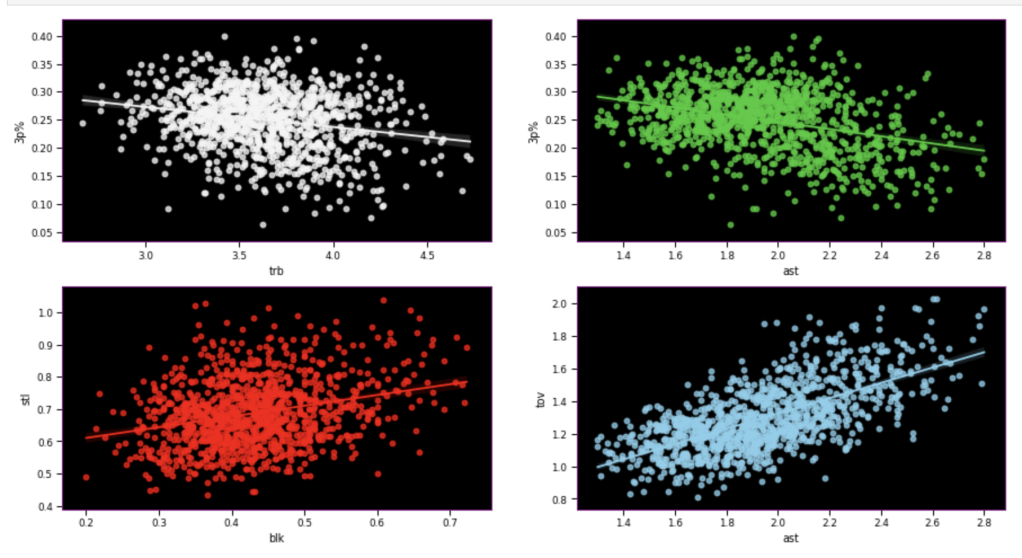
Here, I have another team vs. individual comparison testing various correlations. In terms of my expectations – I hypothesized that 3 point percent would correlate negatively to rebounds, while assists would correlate positively to 3 point percent, blocks would have positive correlation to steal, and assists would have positive correlation with turnovers.
Team dataIndividual data
I seem to be most wrong about assists and 3 point percent while moderately correct in terms of team data.
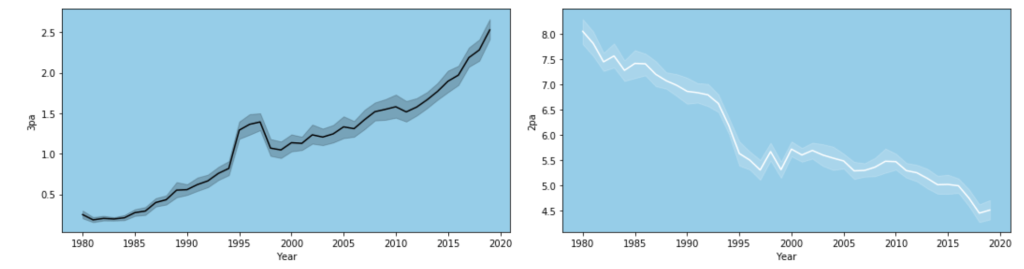
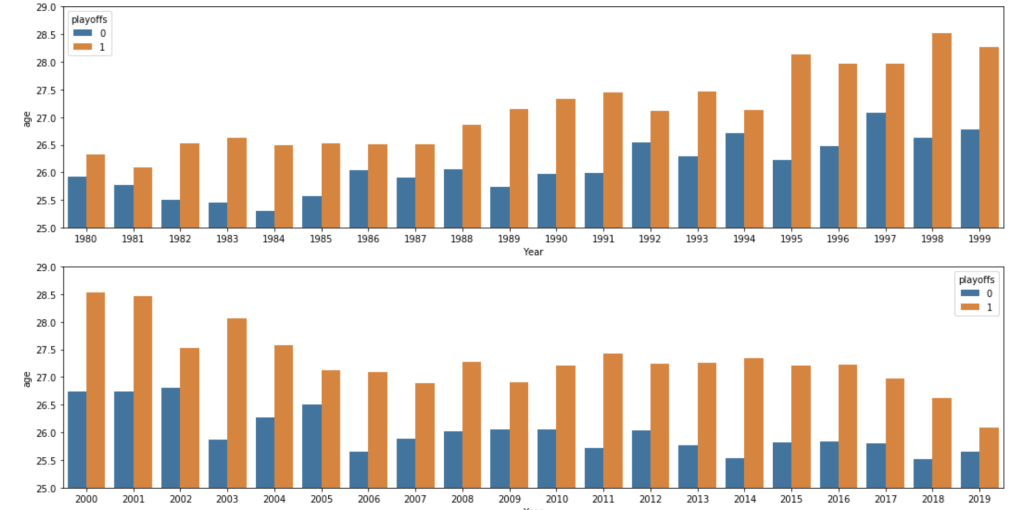
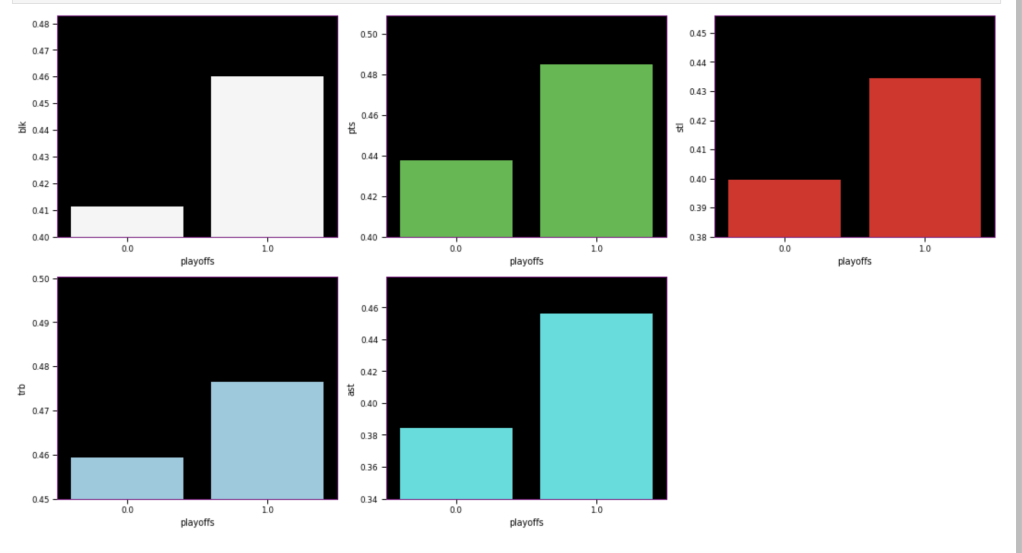
The following graph displays the common differences over ~40 years between playoff teams and non-playoff teams in the five main statistical categories in basketball. However, since the mean and extremes of these categories are all expressed in differing magnitudes, I applied scaling to allow for a more accurate comparison
It appears that the biggest difference between playoff teams and regular teams is in assists while the smallest difference is in rebounding
I’ll look at some individual stats now, starting with some basic sorting.
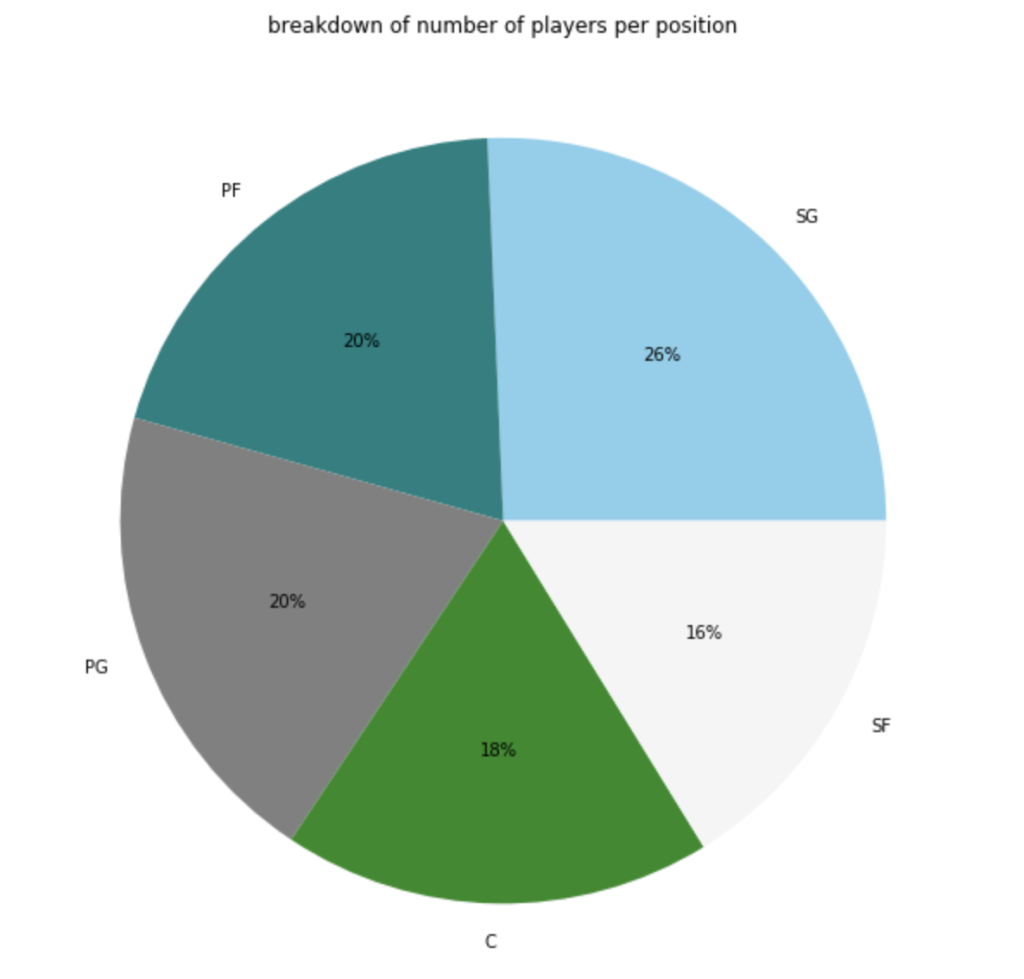
Here’s a graph to see the breakdown of current NBA players by position.
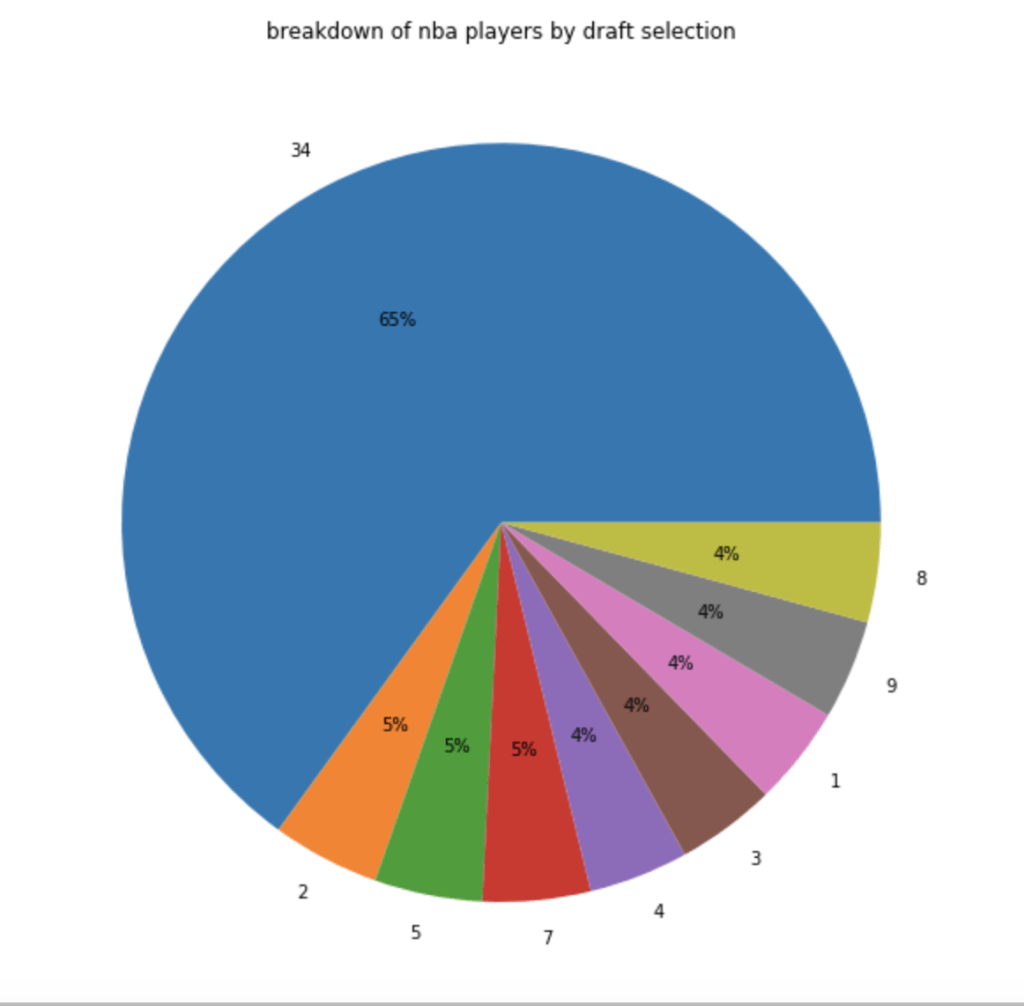
In terms of players by draft selection (with 34 = un-drafted basically):
In terms of how many players actually make the playoffs:
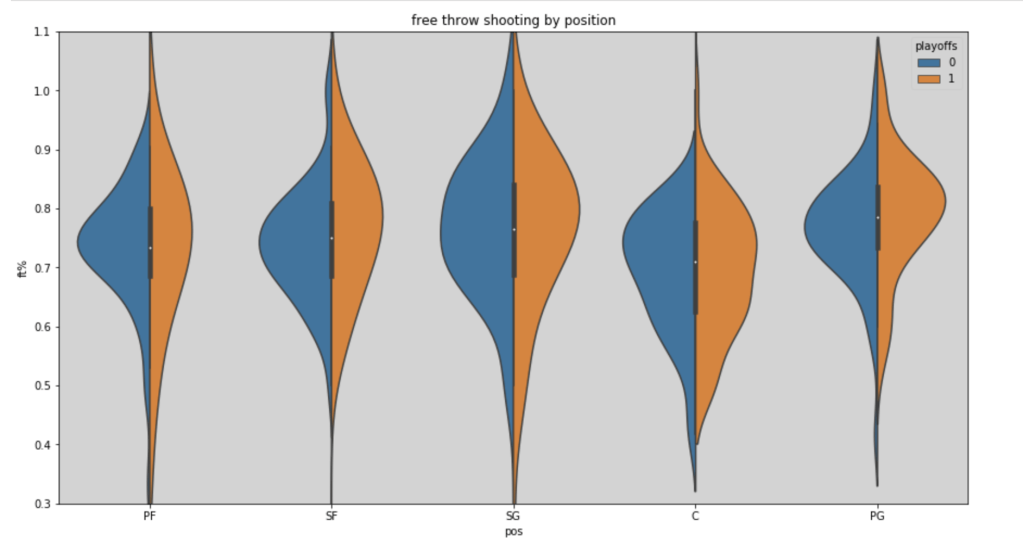
Here’s a look at free throw shooting by position in the 2018-19 NBA season (with an added filter for playoff teams):
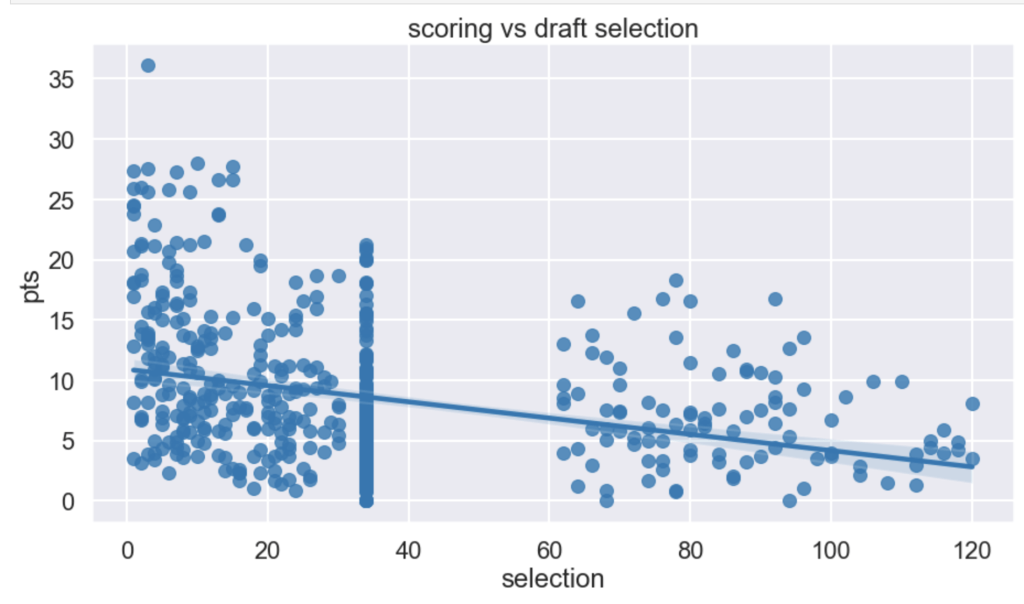
I had a hypothesis that players drafted earlier tend to have higher scoring averages (note that in my graph there is a large cluster of points hovering around x=34. This is because I used 34 as a mean value to fill null for un-drafted players).
It seems like I was right – being picked early in the draft corresponds to higher scoring. I would guess the high point is James Harden at X=3.
Finally I’d like to share the distribution of statistical averages by each of the five major statistics sorted by position:
Model Data
I ran a random forest classifier to get a basic model and then applied scaling and feature selection to improve my models. Let’s see what happend.
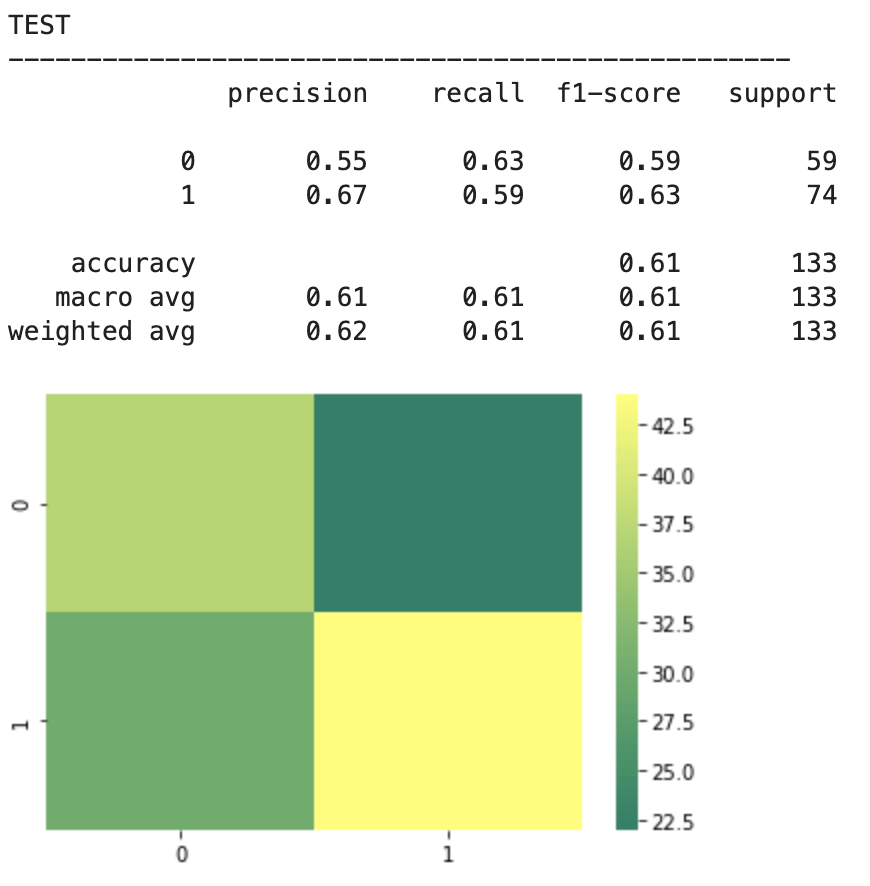
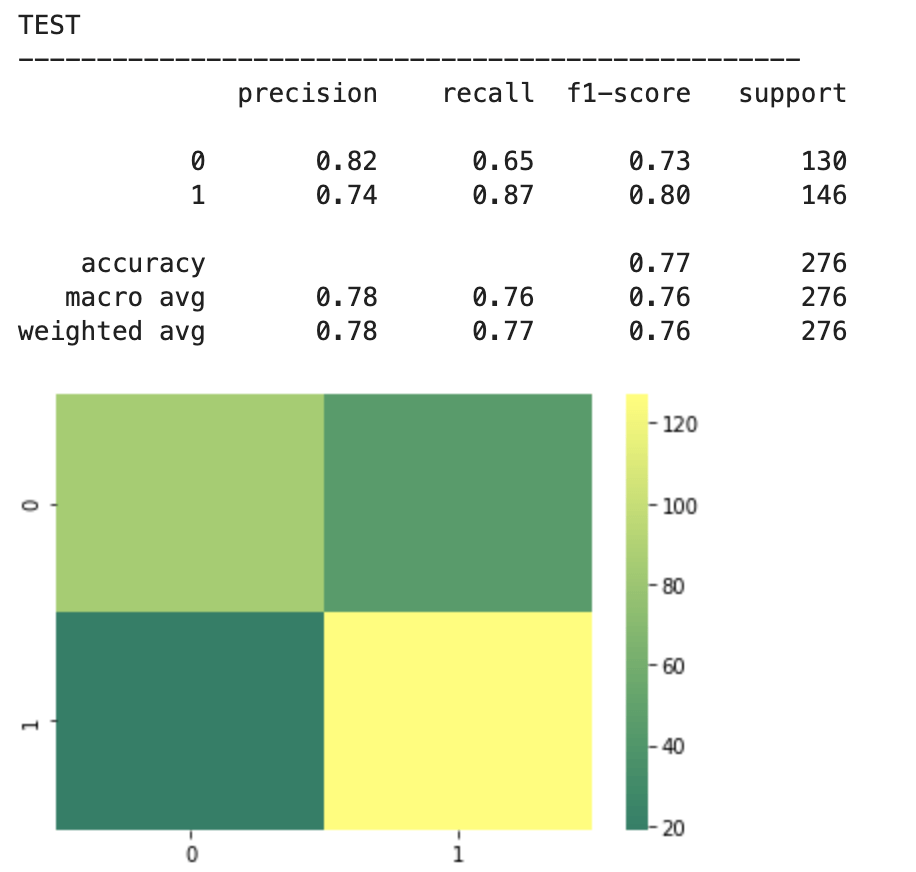
2018-19 NBA players:
The above represents an encouraging confusion matrix with the rows representing predicted data vs columns which represent actual data. The brighter and more muted regions in the top left and bottom right correspond to the colors in the vertical bar adjacent to the matrix and indicate that brighter colors represent higher values (in this color palette). This means that my model had a lot more values whose prediction corresponded to its actual placement that incorrect predictions. The accuracy of this basic model sits around 61% which is a good start. The precision score represents the percentage of correct predictions in the bottom left and bottom right quadrants (in this particular depiction). Recall represents the percentage of correct positions in the bottom right and top right quadrants. In other words recall represents all the cases correctly predicted given that we were only predicting from a pool of teams that made the playoffs. Precision represents a similar pool, but with a slight difference. Precision looks at all the teams that were predicted to have made the playoffs and the precision score represents how many of those predictions were correct.
Next, I applied feature scaling which is a process of removing impacts from variables determined entirely by magnitude alone. For example: $40 is a lot to pay for a can of soda but quite little to pay for a functional yacht. In order to compare soda to yachts, it’s better to apply some sort of scaling that might, for example, place their costs in a 0-1 (or 0%-100%) range representing where there costs fall relative to the average soda or yacht. A $40 soda would be close to 1 and a $40 functional yacht would be closer to 0. Similarly, a $18 billion yacht and an $18 billion dollar soda would both be classified around 1 and conversely a 10 cent soda or yacht would both be classified around 0. A $1 soda would be around 0.5. I have no idea how much the average yacht costs.
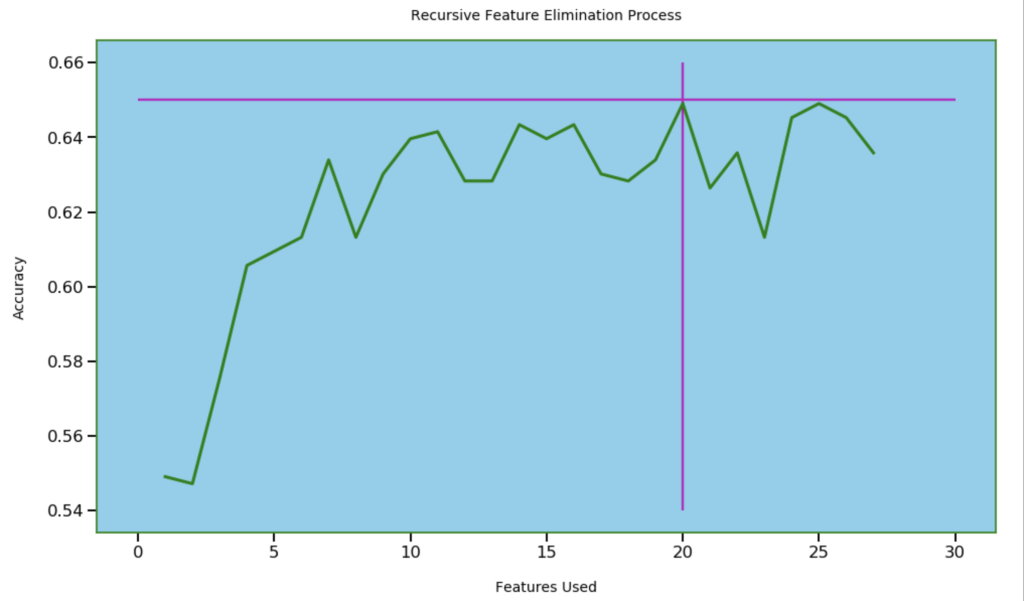
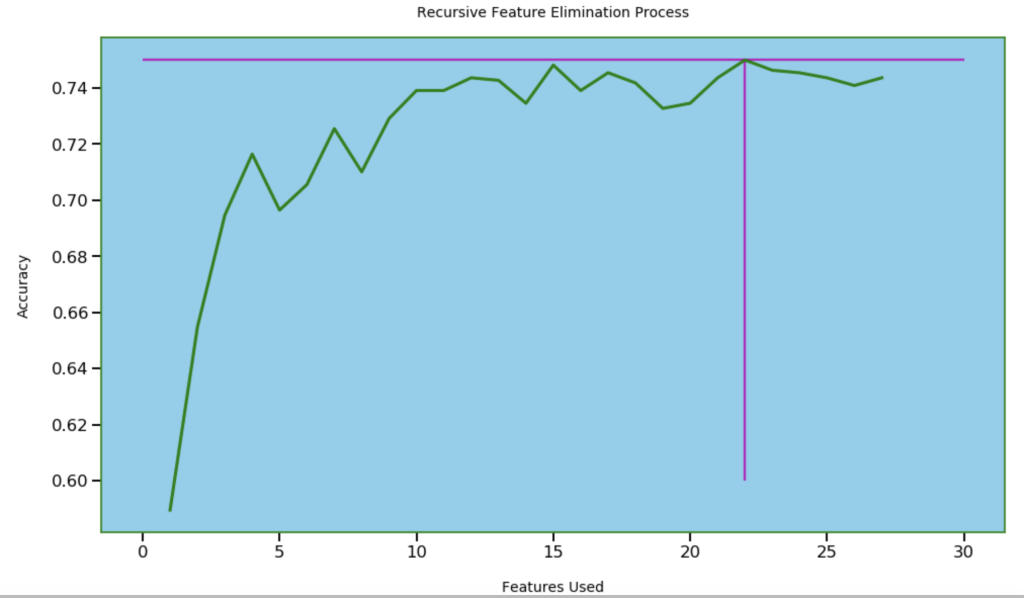
Next, I wanted to see how many features I needed for optimal accuracy. I used recursive feature elimination which is a process of designing a model and the using that model to look for which features may be removed to improve the model.
20 features seems right
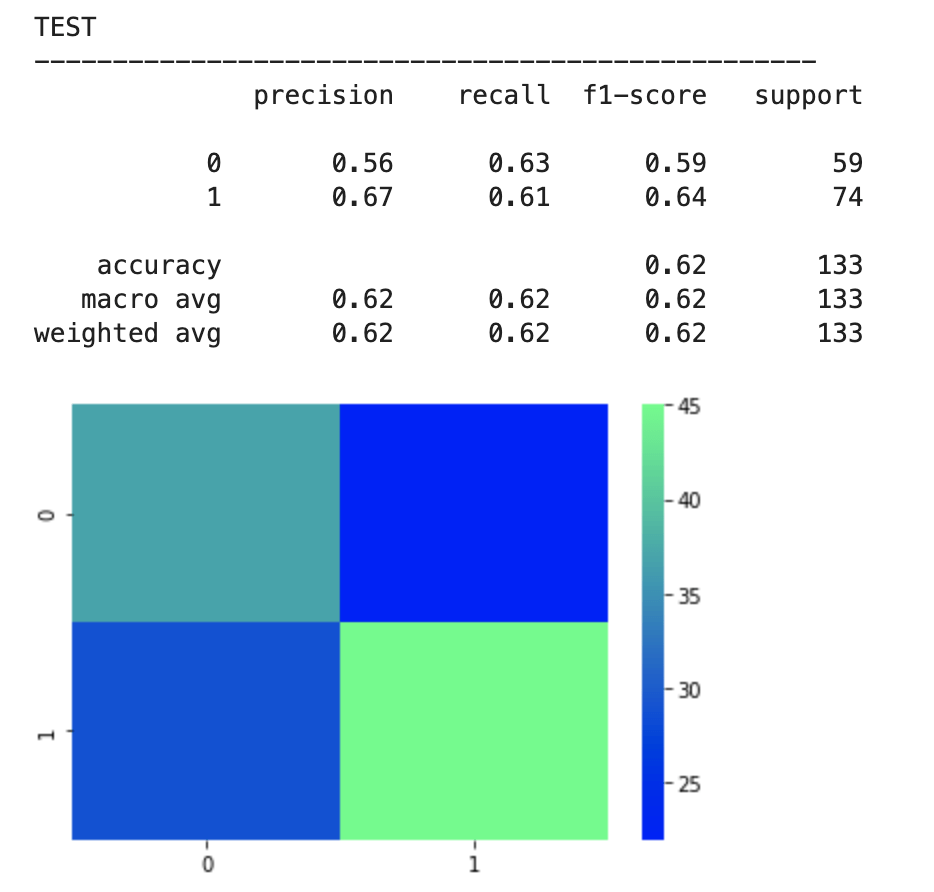
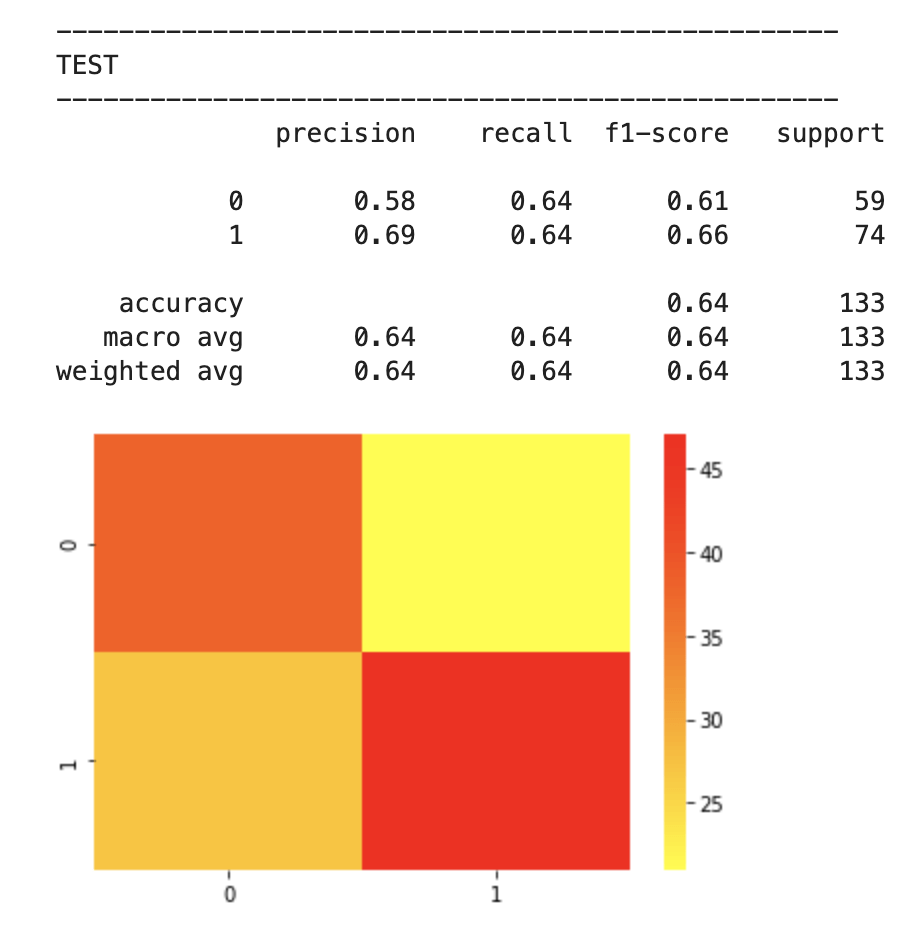
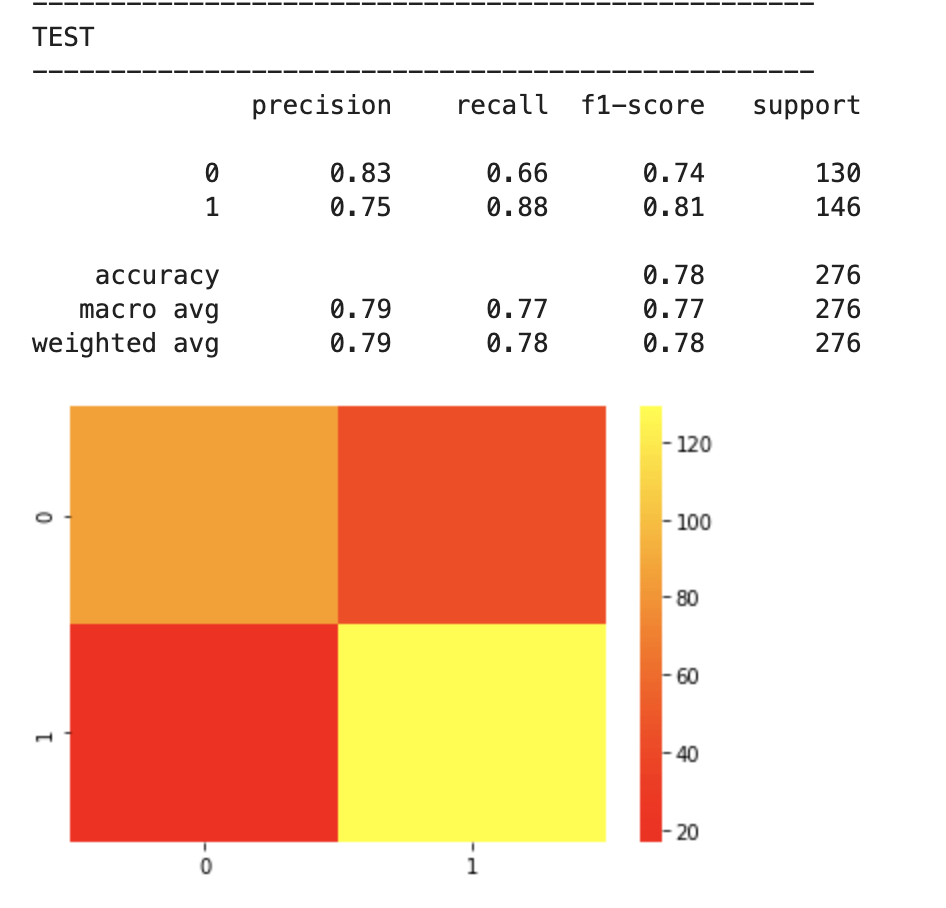
After feature selection, here were my results:
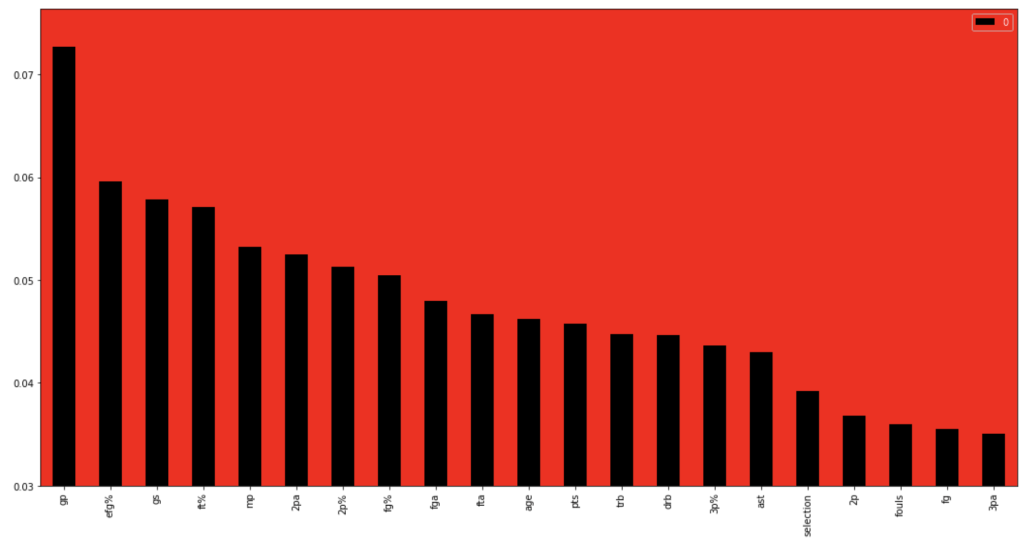
64% accuracy is not bad. Considering that a little over 50% of all NBA players make the playoffs every year, I was able to create a model that, without any team context at all, can predict to some degree which players will earn a trip to the playoffs. Let’s look at what features have the most impact. (don’t give too much attention to vertical axis values). I encourage you to keep these features in mind for later to see if they differ from the driving influences for the larger scale, team-oriented model.
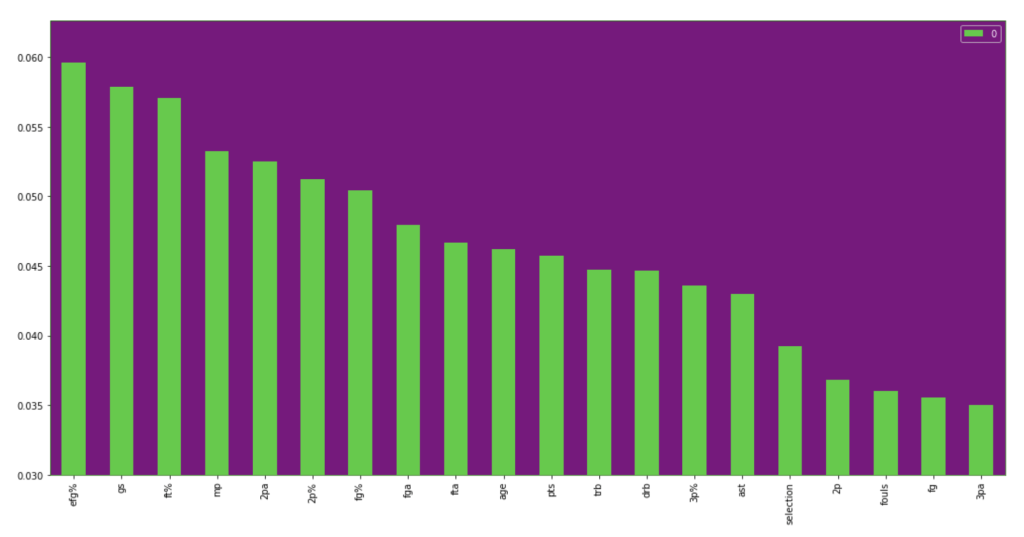
If I take out that one feature at the beginning that is high in magnitude for feature importance, we get the following visual:
I will now run through the same process with team data. I will skip the scaling step as it didn’t accomplish a whole lot.
First model:
Feature selection.
Results:
78% accuracy while technically being a precision model
Feature importance:
Feature importance excluding age:
I think one interesting observation here is how much age matters in a team context over time, but less in the 2018-19 NBA season. Conversely, effective field goal percent had the opposite relationship.
Conclusion
I’m excited for sports to be back. I’m very curious to see the NBA playoffs unfold and would love to see if certain teams emerge as dark horse contenders. Long breaks from basketball can either be terrible or terrific. I’m sure a lot of players improved while others regressed. I’m also excited to see that predicting playoff chances both on individual and team levels can be done with an acceptable degree of accuracy. I’d like to bring this project full circle. Let’s look at the NBA champion San Antonio Spurs from 2013-14 (considered a strong team-effort oriented team) and Devin Booker from 2018–19. I don’t want to spend too much time here but let’s do a brief demo of the model using feature importance as a guide. The average age of the Spurs was two years above the NBA average with the youngest members of the team being 22, 22, and 25. The Spurs led the NBA in assists that year and were second to last in fouls per game. They were also top ten in fewest turnovers per game and free throw shooting. Now, for Devin Booker. Well, you’re probably expecting me to explain why he is a bad team player and doesn’t deserve a spot in the playoffs. That’s not the case. By every leading indicator in feature importance, Devin seems like he belongs in the playoffs. However, let’s remember two things. My individual player model was less accurate and Booker sure seems like an anomaly. However, I think there is a bigger story here, though. Basketball is a team sport. Having LeBron James as your lone star can only take you so far (it’s totally different for Michael Jordan because Jordan is ten times better, and I have no bias at all as a Chicago native). That’s why people love teams like the San Antonio Spurs. They appear to be declining now as their leaders have recently left the team in players such as Tim Duncan and Kawhi Leonard. Nevertheless, basketball is still largely a team sport. The team prediction model was fairly accurate. Further, talent alone seems like it is not enough either. Every year, teams that make the playoffs tend to have older players. Talent and athleticism is generally skewed toward younger players. Given these insights, I’m excited to have some fresh eyes with which to follow the NBA playoffs.
Understanding the main influences and driving factors behind how a phone’s price is determined.
Introduction
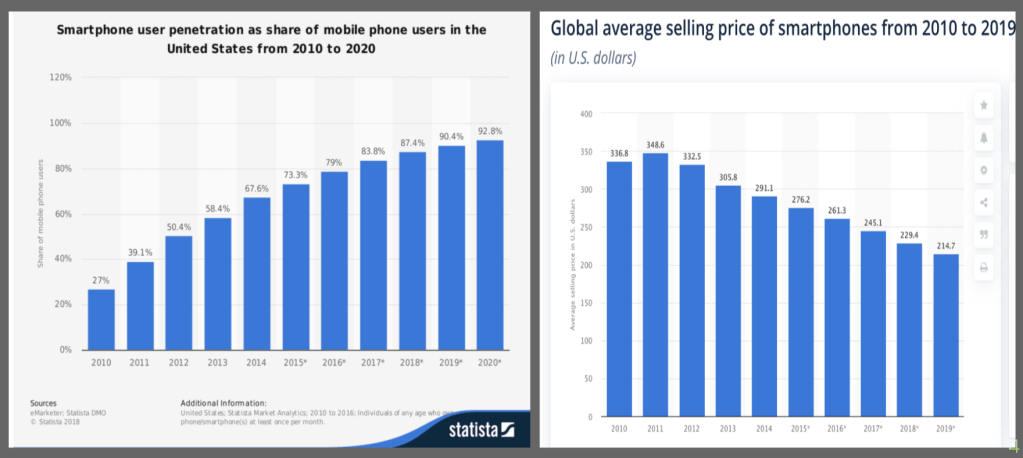
If you made it this far it means you were not completely turned off by my terrible attempt to use a pun in the title and I thank you for that. This blog will probably be pretty quick I think. Recently, I have been seeing some buzz about the phone pictured above; the alleged iPhone 12. While every new iPhone release and update is exciting (yes – I like Apple and have never had an android), I have long been of the opinion that there hasn’t been too much major innovation in cell phones in recent years. While there have been new features added or camera upgrades, there are few moments that stick out as much as when Siri was first introduced. (I remember when I tried to use voice recognition on my high school phone before everyone had an iPhone). Let’s look at the following graph for a second:
The graph above indicates that as popularity in smartphones has gone up, prices have declined. I think that there are many influences here, but surely the lack of major innovation is one reason why no one is capitalizing on this obvious trend and creating phones that are allowed to be more expensive because of what they bring to the table. This led me to my next question; what actually drives phone pricing? iOS 9 still sticks out to me all these years later because I loved the music app. However, it could be that others care nothing about the music app and are more interested in other features like camera quality and I was really interested in seeing what actually mattered. Conveniently, I was able to find some data from kaggle.com and could investigate further.
Data Preparation
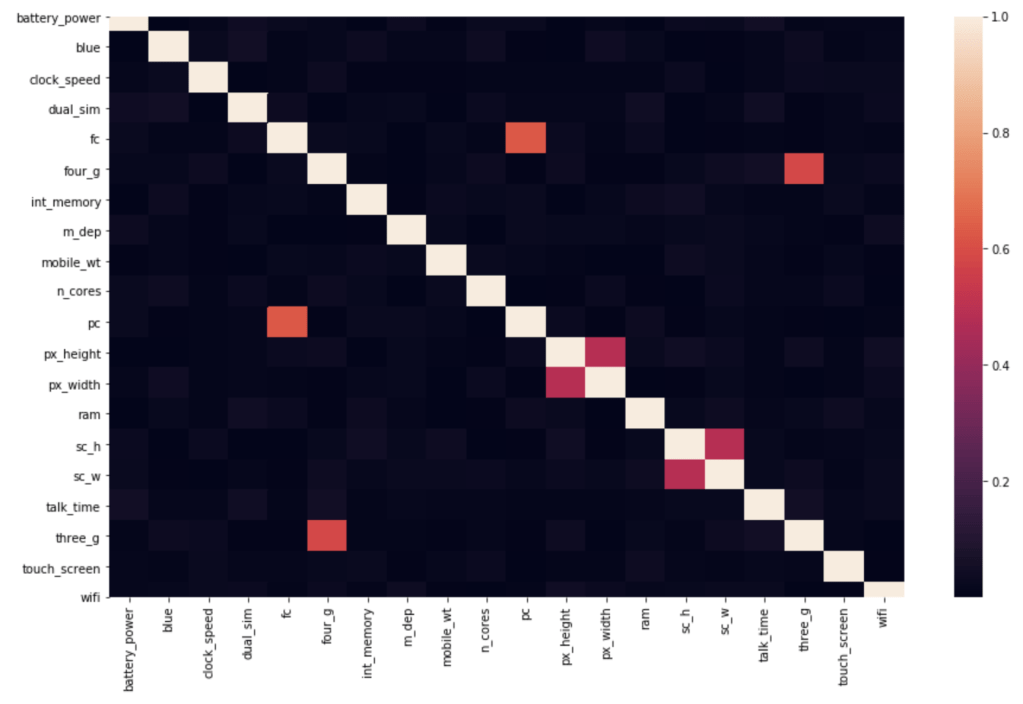
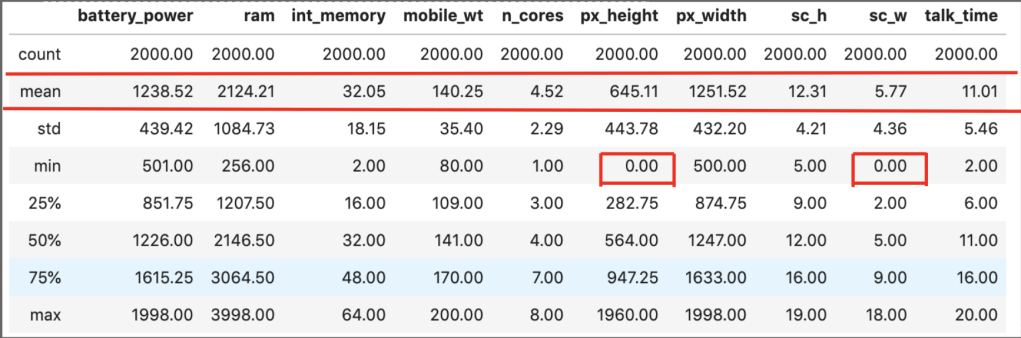
I mentioned my source: kaggle.com. My data contained the following features as described by kaggle.com (I’ll add descriptions in parentheses when needed but also present the names as they appear in the data): battery_power, blue (presence of bluetooth), clock_speed (microprocessor speed), dual_sim (dual sim support or not), fc (front camera megapixels), four_g (presence of 4G), int_memory (storage), m_dep (mobile depth in cm), n_cores (number of cores of processor), pc (primary camera megapixels), px_height (pixel resolution height), px_width, ram, sc_h (screen height), sc_W (screen_width), talk_time (longest possible call before battery runs out), three_g (presence of 3G), touch_screen, wi_fi. The target feature is price range which consists of 4 classes each representing an increasing general price range. In terms of filtering out correlation – there was surprisingly no high correlation to filter out.
There were some other basic elements of data preparation that are not very exciting so will not be described here. I would like to point out one weird observation, though:
In those two smaller red boxes, it appears that some phones have a screen width of zero. That doesn’t really make any sense.
Model Data
I ran a coupe different models and picked the logistic regression model because it worked best. You may notice that when I post my confusion matrix and metrics that precision = recall = f1 = accuracy. That is always the case with evenly balanced data. Even after filtering outliers I had a strong balance in my target class.
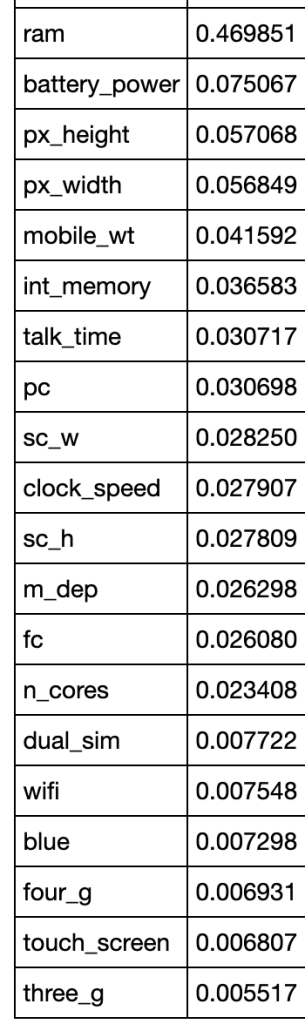
In terms of determining what drives pricing by using coefficients determined in logistic regression:
I think these results make sense. At the top you see things like RAM and battery power. At the bottom you see things like touch screen and 3G. Almost every phone includes these features nowadays an there is nothing special about a phone having those features.
Conclusion
We now have an accurate model that can classify the price range of any phone given it’s features and we also know what features have the biggest impact on price. If companies are stuck on innovation, they could just keep upping the game with things like higher RAM, I suppose. I think the next step in this project is to collect more data on other features not yet included but to also take a closer look at what the specific differences in each iteration of the iPhone were as well as how the operating systems they run on have evolved. I actually saw a video today about iOS 14 and it doesn’t look to be that innovative. Although, I am curious to see what will happen as Apple begins to develop their own chips in place of Intel ones. At the very least, we can use the model established here as a baseline to be able to understand what will allow companies to charge more for their phones in the absence of more impactful innovation.
Understanding style options available in Seaborn that can enhance your explanatory graphs and other visuals.
Introduction
Welcome to my blog! Today, I will be discussing ways to leverage Seaborn (I will often use the ‘sns’ abbreviation later on) into spicing up python visuals. Seaborn [and Matplotlib – abbreviated as ‘plt’] are powerful libraries that can enable anyone to swiftly and easily design stunning and impressive visuals that can tell interesting stories and inspire thoughtful questions. Today, however, I would like to shift the focus to a different aspect of data visualizations. I may one day (depending on when this is read – maybe it happened already) write about all the amazing things Seaborn can do in terms of telling a story, but today that is not my focus. What inspired me to write this blog is that all my graphs used to all be… boring. Well, I should qualify that. When I use Microsoft Excel, I enjoy taking a “boring” graph and doing something exciting like putting neon colors against a dark background. In python, my graphs tend to be a lot more exciting in terms capability in describing data but were boring visually. They were all in like red, green, and blue against a blank white background. I bet a lot of readers out there may know some ways to spice up graphs by enhancing aesthetics but I would like to discuss that very topic today for any readers who may not really know these options are available (like I didn’t at first) and hopefully, even provide some insights to more experienced python users. Now, as a disclaimer: this information can all be found online in Seaborn documentation, I’m just reminding some people it’s there. Another quick note: Matplotlib and Seaborn go hand in hand but this blog will focus on Seaborn. I imagine at times it will be implied that you may or may not also need Matplotlib. Okay, let’s go!
(I hope you are comfortable with scatter plots and regression plots). The plan here is to go through all the design aesthetics functions in Seaborn (in particular – style options) and talk about how to leverage them into spicing up data visualizations. One quick note here: I like to use the ‘with’ word in python as this does not change all my design aesthetics for my whole notebook, just that one visual or set of visuals. In other words – if you don’t write ‘with’ your changes will be permanent. Let me show you what I mean:
Using no design aestheticsUsing ‘with’ keyword
It may be annoying to always add the with keyword, so you obviously can just set one style for your whole notebook. I’ll talk about what happens when you want to get rid of that style later on.
One more note: You may notice I added a custom color. Below I have included every basic python color and color palette (at least, I think I have). I’m fairly certain you can create custom colors but that is beyond the scope of this blog (I may blog bout that some other time and that very blog may already exist depending on when this is read, so keep your eyes open). The reason that the color palettes are in an error message is to give any reader a trick to remember them all. If you use an incorrect color palette (which will be discussed shortly), then python will give you your real options. I really like this feature. Just keep in mind that some of these, like ‘Oranges,’ go on past the end of the line, so make sure that doesn’t confuse you. You may also notice that every palette has a ‘normal’ color and a second ‘normal_r’ color. Look at ‘Blues’ and ‘Blue_r,’ for example. All it means is that the colors are reversed. I’m not familiar with Blues, but if it were to start with light blue and move toward dark blue, I imagine the reverse would start at dark and move to light. Color palettes sometimes can be ineffective if you don’t need (or don’t want) a wide range of colors. Example: my graph above of a regression plot. In the case that color palettes are of little value, I have provided the names of colors as well.
Okay, let’s start!
sns.reset_defaults()
This is probably the easiest one to explain. If you have toyed with your design aesthetic settings, this will reset everything.
sns.reset_orig()
This function looks similar to the one above but is slightly different in its effect. According to the Seaborn documentation, this function resets all style but keeps any custom rcParams. To be honest, I tried to put this in action and see how it was different than reset_defaults( ). I was not very successful. In case you want to learn more about what rcParams are, check out this link: https://matplotlib.org/3.2.2/users/dflt_style_changes.html. I think rc stands for ‘Run & Configure.’ I’ll need to investigate this further. If any readers understand this and how it is different from reset_defaults(), please feel free to reach out.
sns.set_color_codes()
This one is quick but interesting. My understanding is that it allows you to control how Matplotlib colors are interpreted. Let me show you what I mean:
‘muted’ palette‘pastel’ palette
The change above is subtle, but can be effective, especially if you add further customizations. In total, color code options include: deep, muted, pastel, dark, bright, and colorblind.
I’d like to record a quick realization here: while writing this blog I learned that there are also many Matplotlib customization options that I didn’t know of before and, while that is beyond the scope of this blog, I may write about that later (or have already written about it depending on when this blog is being read). I think the reason I never noticed this is because, and I’m just thinking out loud here, I only ever looked at the matplotlib.pyplot module and never really looked at modules like matplotlib.style. I’m wondering to myself now if the main virtue of Seaborn (as opposed to Matplotlib) is that Seaborn can generate more descriptive and insightful visuals as opposed to ones with creative aesthetics.
sns.set_context()
This one is very similar to one yet to be discussed. Anyways, to quote the documentation: “This affects things like the size of the labels, lines, and other elements of the plot, but not the overall style.” There are 4 default contexts: talk, paper, notebook and poster. This function also (can) take the following parameters: context (things like paper or poster), font_scale (making the font bigger or smaller), and rc (a dictionary of other parameters discussed earlier used “to override the values in the preset [S]eaborn context dictionaries” according to the documentation). Here are some visuals:
notebook contextposter contextrc params in poster contextrc params changing line size in poster context
sns.plotting_context()
This function has the same basic application as the one above and even has the same parameters. However, as will be the trend with other topics, by typing the function above you will actually get a return value. To be clear, by typing sns.plotting_context() (I’ll have a visual) you will get a return value of a dictionary that provides you with all the rcParams available for plotting context. So not only can you set a context, but you can also see your options if you forget what’s available. One difference I have found between this function and the one above is that this one works (maybe only works?) with something like the ‘with’ keyword as opposed to the one before which functions independently of that keyword. (I’ll need to do some more research here). In any case, we’re going to see another dictionary later, but here is our first one.
sns.set_style()
I’m going to skip this, you’ll understand why.
sns.axes_style()
The two functions listed above basically work together in the same way that set context and plotting context do. The default options for setting an axes style are: darkgrid, whitegrid, dark, white, and ticks. In addition, in the axes_style version, you can just enter sns.axes_style() to return a dictionary of all your additional options. If you look back at the regplots at the beginning of the blog you may notice that I leveraged the darkgrid option and I encourage you to scroll back up to see it in action.
All I did in the graph above was set a black background, but now the graph looks far more exciting and catchy than any of the ones above.
I’d like to record another thought here. It really does seem that the ‘with’ keyword only works with some functions as described above. Unless I am missing some key point, I find it works with things like axes_style and plotting_context but not set_style and set_context. I’m going to have to dive deeper into what that means about the functions and how they are different.
sns.set()
Today’s blog is about style options and this is the last one to cover (although I didn’t really go in any particular order). I think that this function is a bit of a catch-all. The parameters are: context, style, palette, font, font_scale. The documentation says that context and style correspond to the parameters in the axes_style and plotting_context ‘dictionaries’ cited above. I’d like to also look at the palette option. I alluded to this earlier in the blog with all the available color palettes. In the documentation color palette is not part of the style options. I would still encourage using the (with) sns.color_palette() function (that can use the ‘with’ keyword) to be able to set interesting color palettes like the ones listed above. It appears that this function (back to sns.set()) doesn’t easily work with the ‘with’ keyword. Also, the color_codes parameter is a true-false value, but it’s not entirely clear to me how it works. Here’s what the documentation says: ‘If True and palette is a Seaborn palette, remap the shorthand color codes (e.g. “b”[lue], “g[reen]”, “r[ed]”, etc.) to the colors from this palette.’ I found this link for all the fonts available for Seaborn / Matplotlib: http://jonathansoma.com/lede/data-studio/matplotlib/list-all-fonts-available-in-matplotlib-plus-samples/. When I provide some visuals, I encourage you to pay attention to how I enter the font options.
set background colorset contextThe palette only shows one color in this case so I will provide some palette examples laterset font and font size – unlike colors, however, fonts are not entered as one word – they have spaces. A color is written as ‘forestgreen’ as opposed to ‘forest green’ but fonts work differentlyset grid color with rcParamsI’ve used the icefire palette referenced above in the error messagehere is icefire_r
You may notice how I added the palette in the function that makes the graph. Yes, it is an option. However, if you want to make a lot of graphs it can be inefficient. I suppose one interesting option would be to create a list of palettes and just loop through them if you want to keep mixing things up.
Conclusion
Creating visuals to tell a story or identify a trend is exciting and important to data science inquiries. If this is indeed the case, why not make your visuals catchy and exciting? People are drawn to things that look ‘cool.’ In addition, while I know the focus in this blog was on style, we did briefly explore color options. I found this blog that quickly talks about strategically planning how you use colors and color palettes in your visuals: https://medium.com/nightingale/how-to-choose-the-colors-for-your-data-visualizations-50b2557fa335. Like I said, though, the focus here has been on style options. Writing this blog has been a bit of a learning experience for me as well. I have realized that there are a lot more options to spice up graphs and make them more interesting and meaningful. For example, I probably haven’t taken full advantage of all the options available in Matplotlib and its various modules. I’m going to have to do more research on various topics and possibly update and correct parts of my blog post here, but I think this is a good starting point.
Thanks for reading and have a great day.
By the way… here’s some graphs I made using Matplotlib and Seaborn:

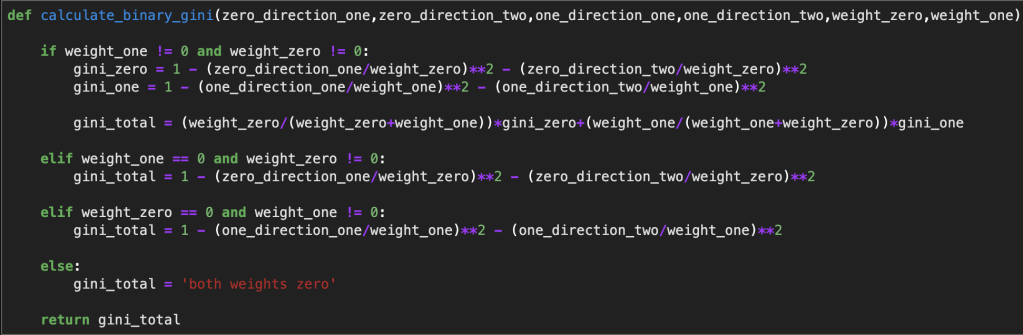

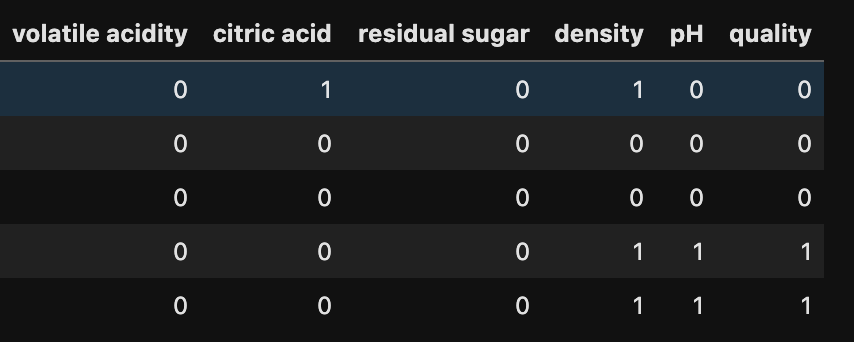
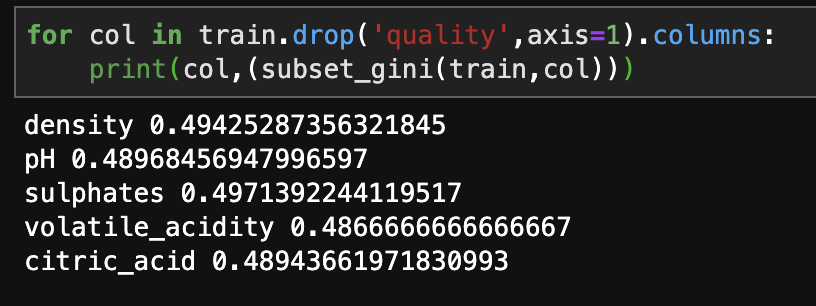
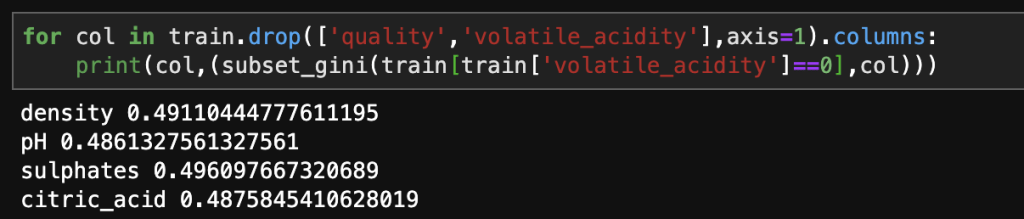
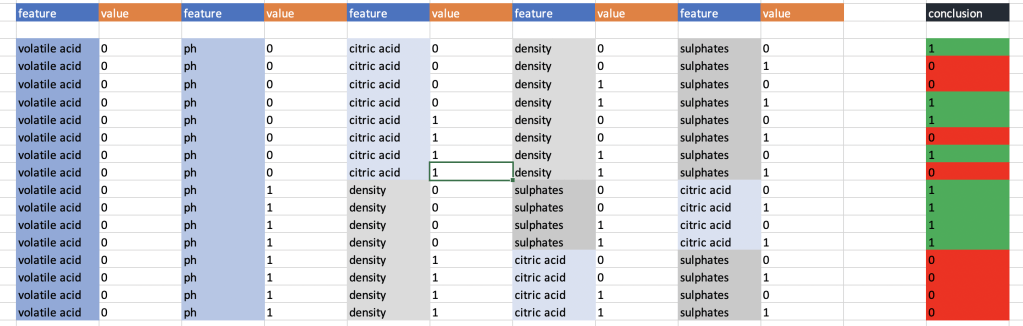
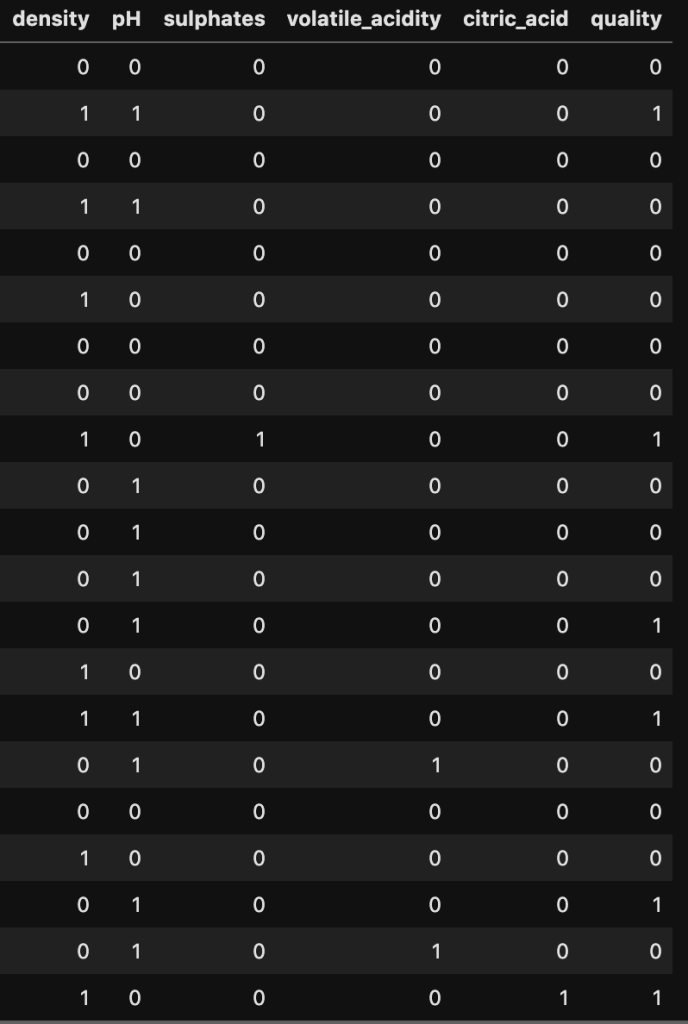

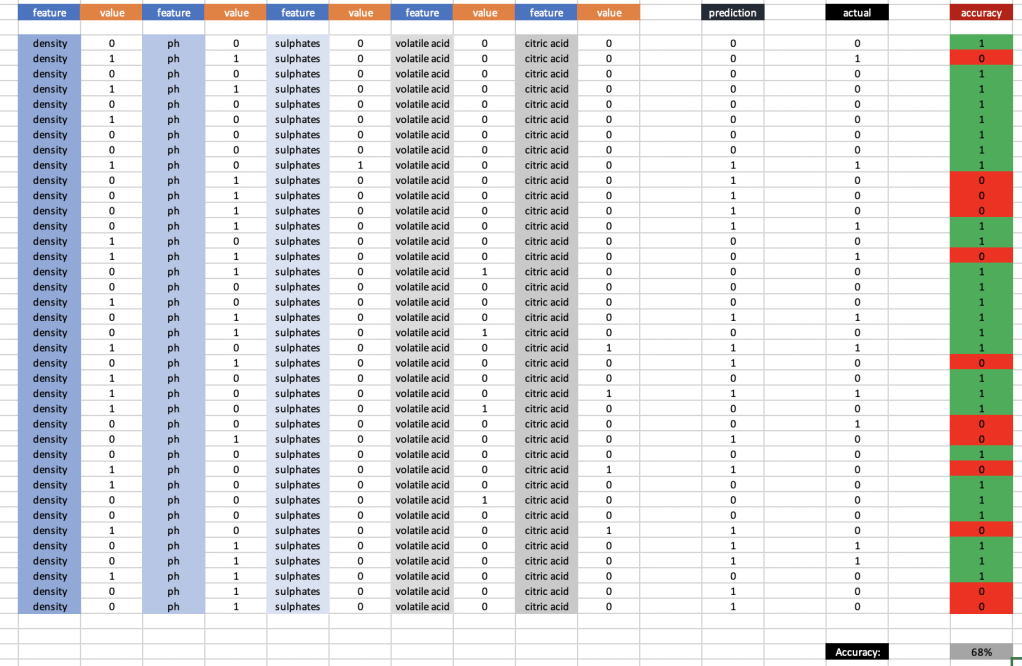




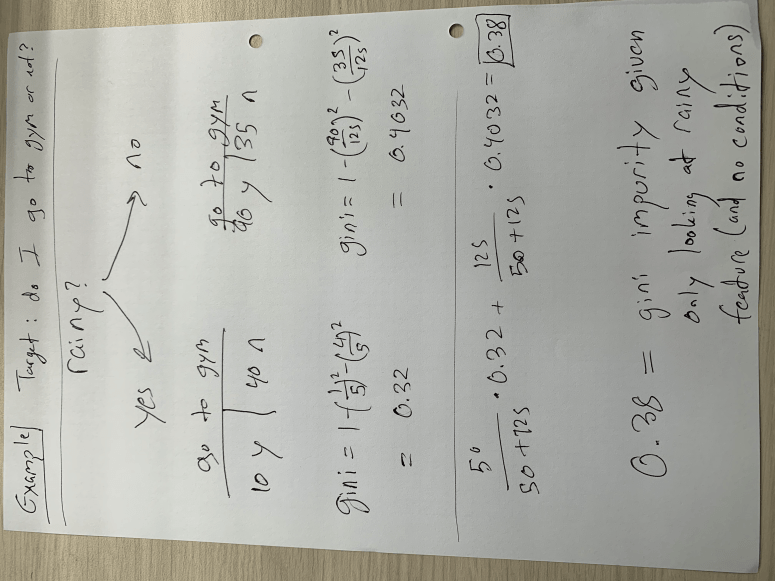



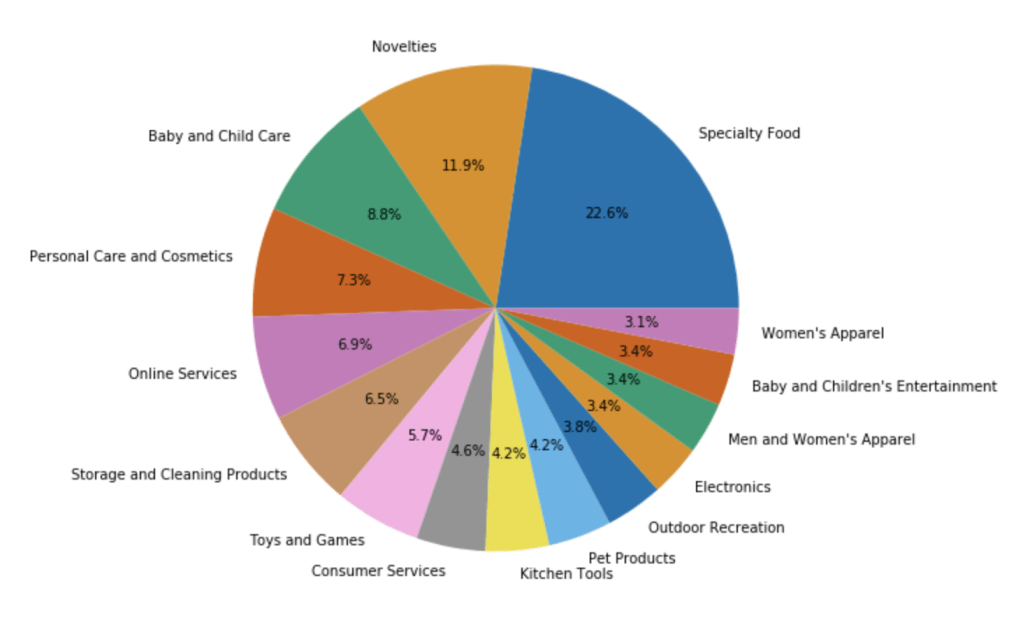
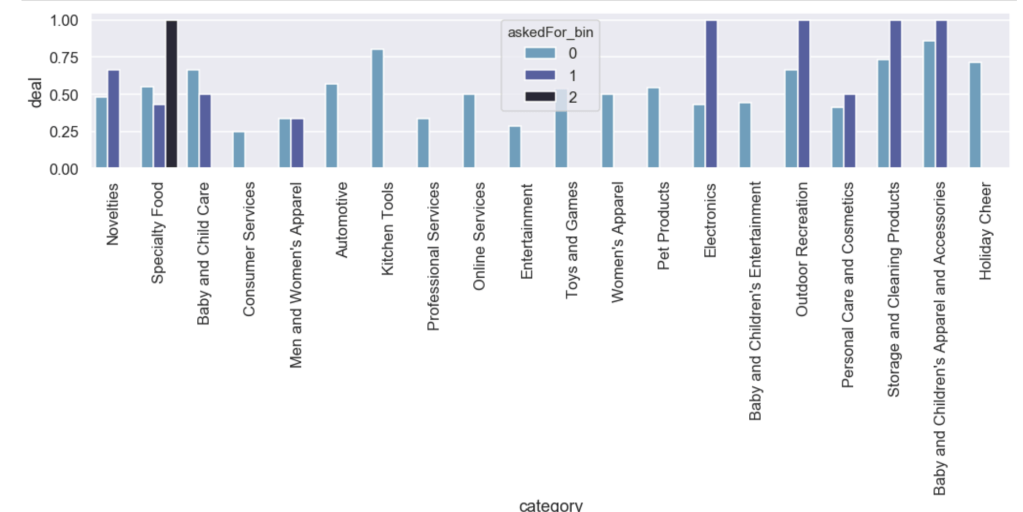
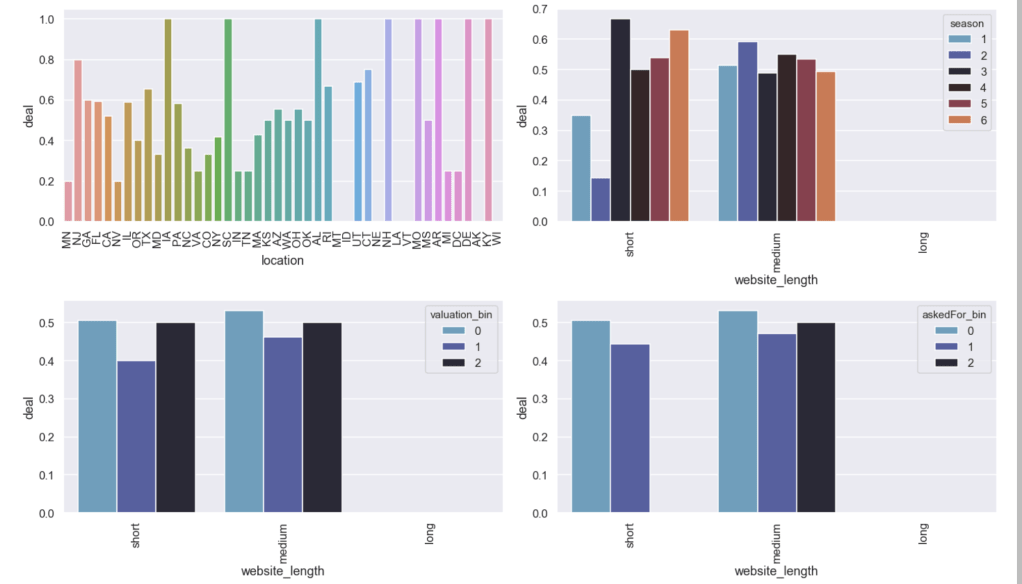
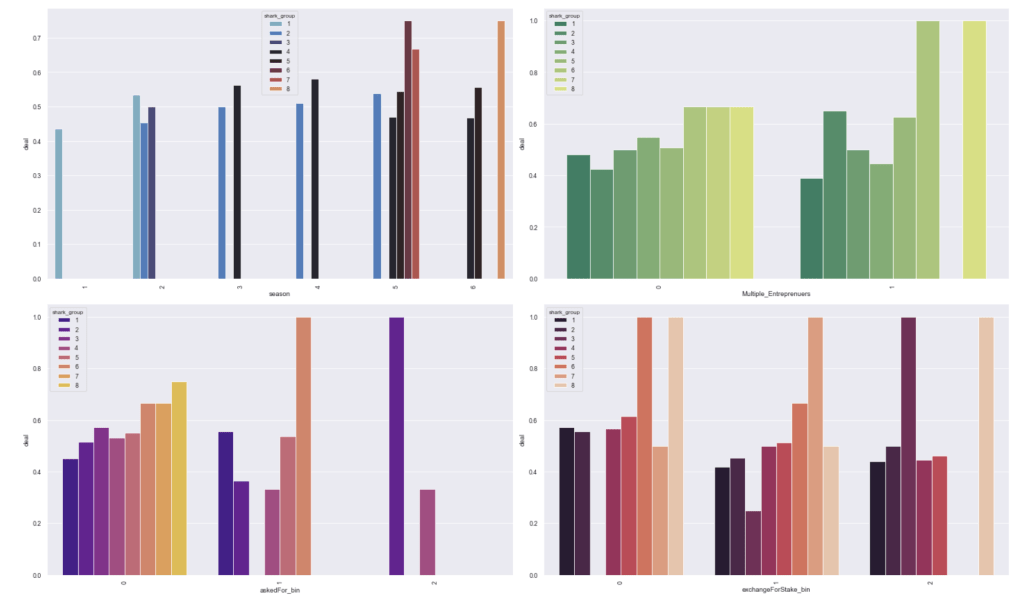
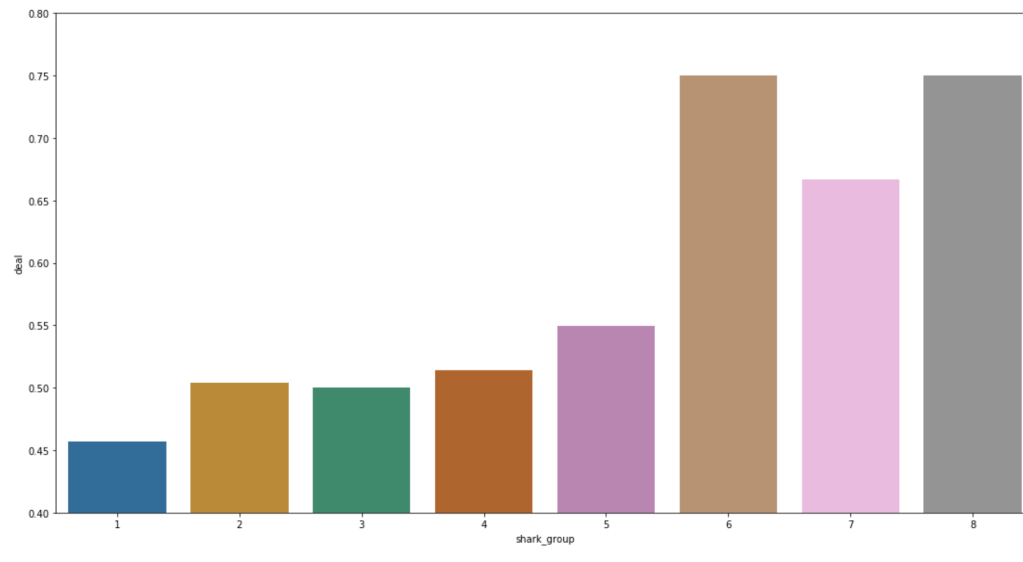
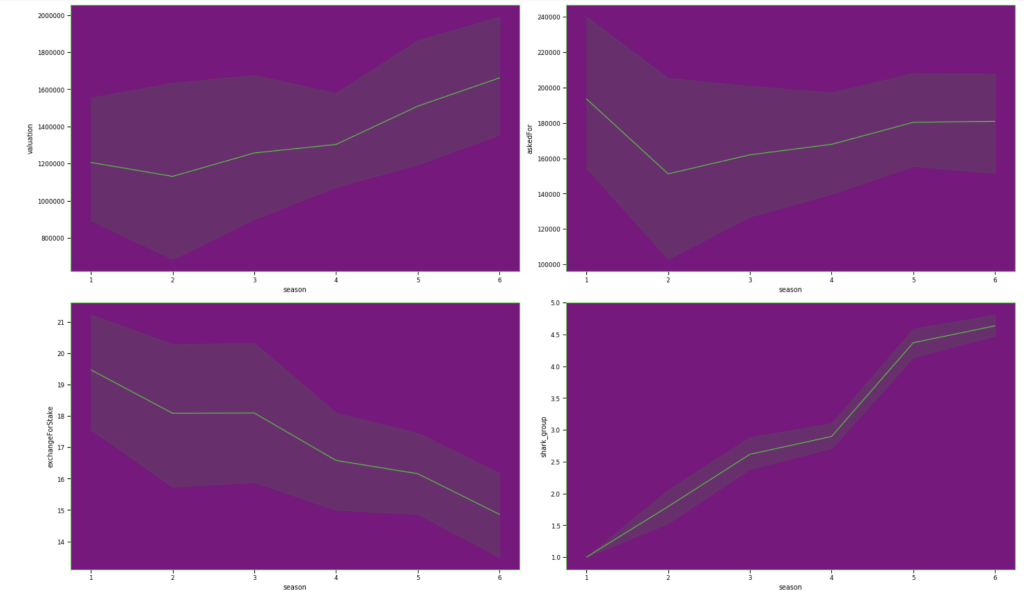
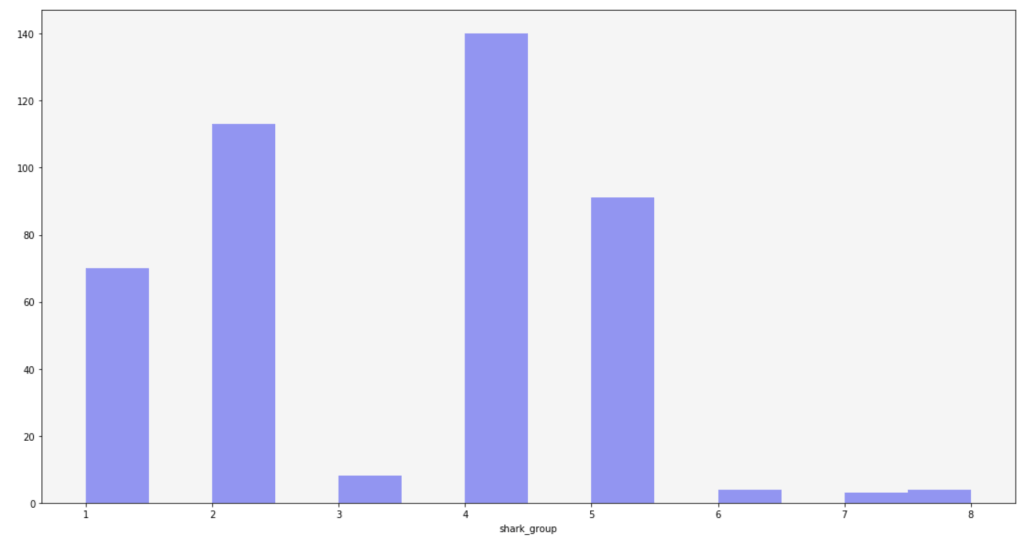
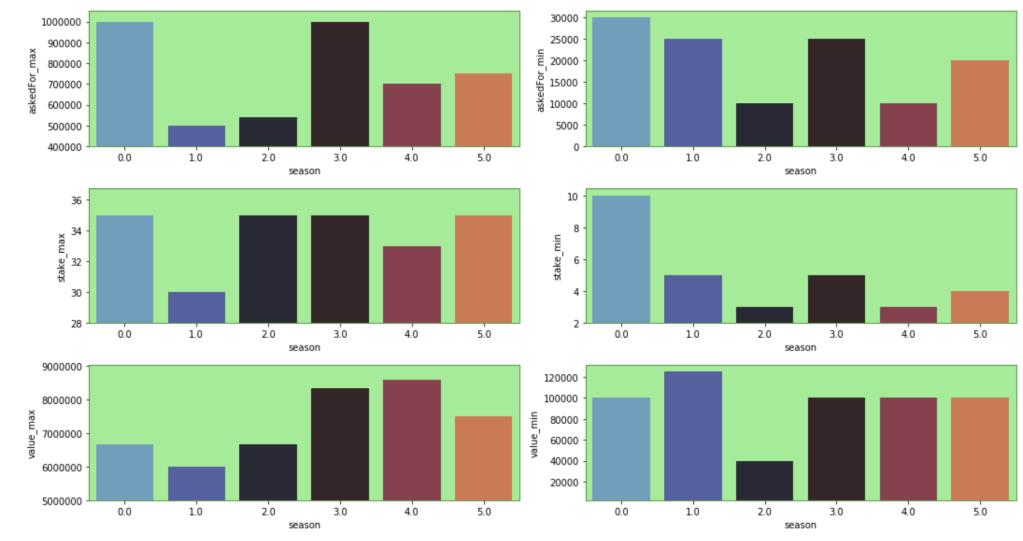
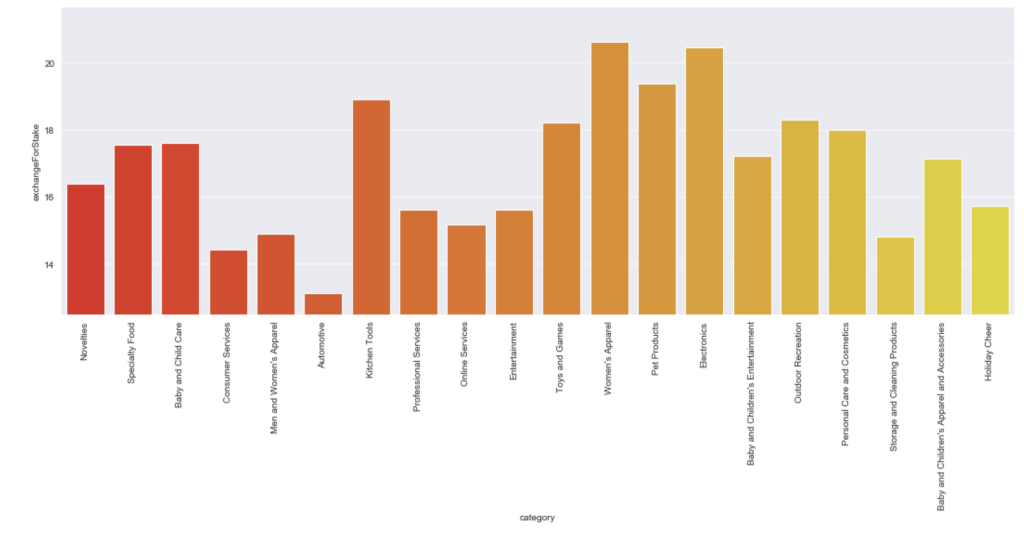
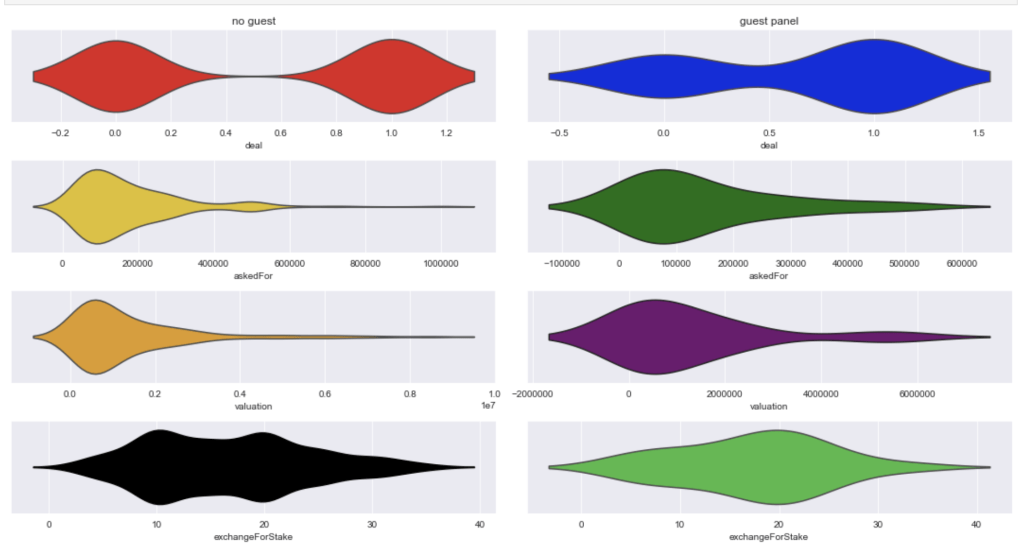
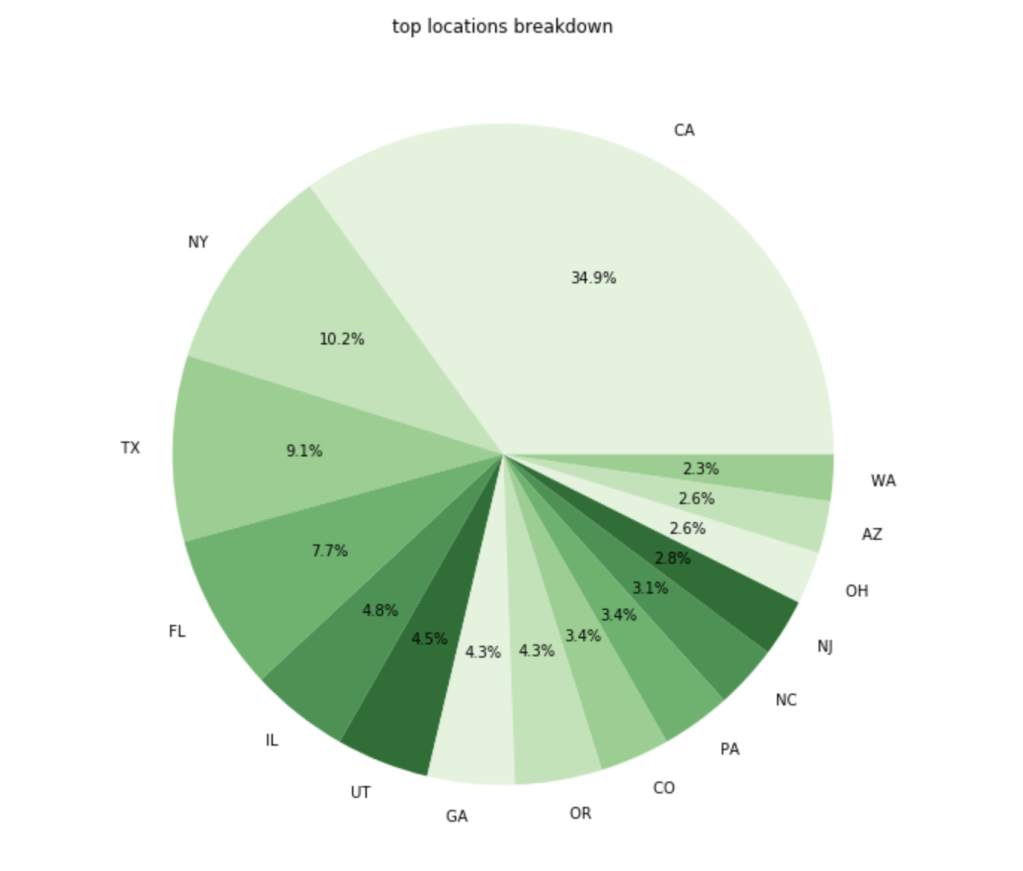
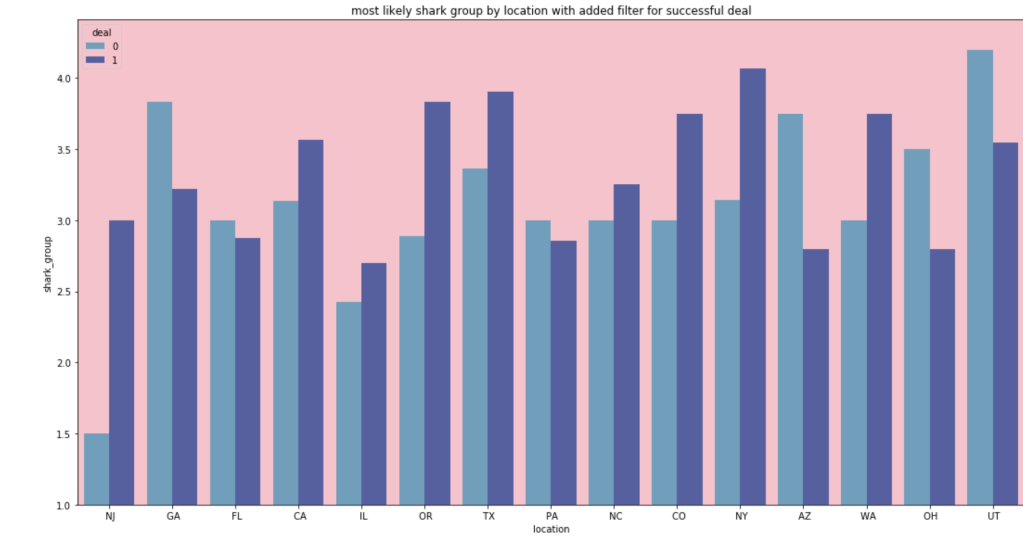
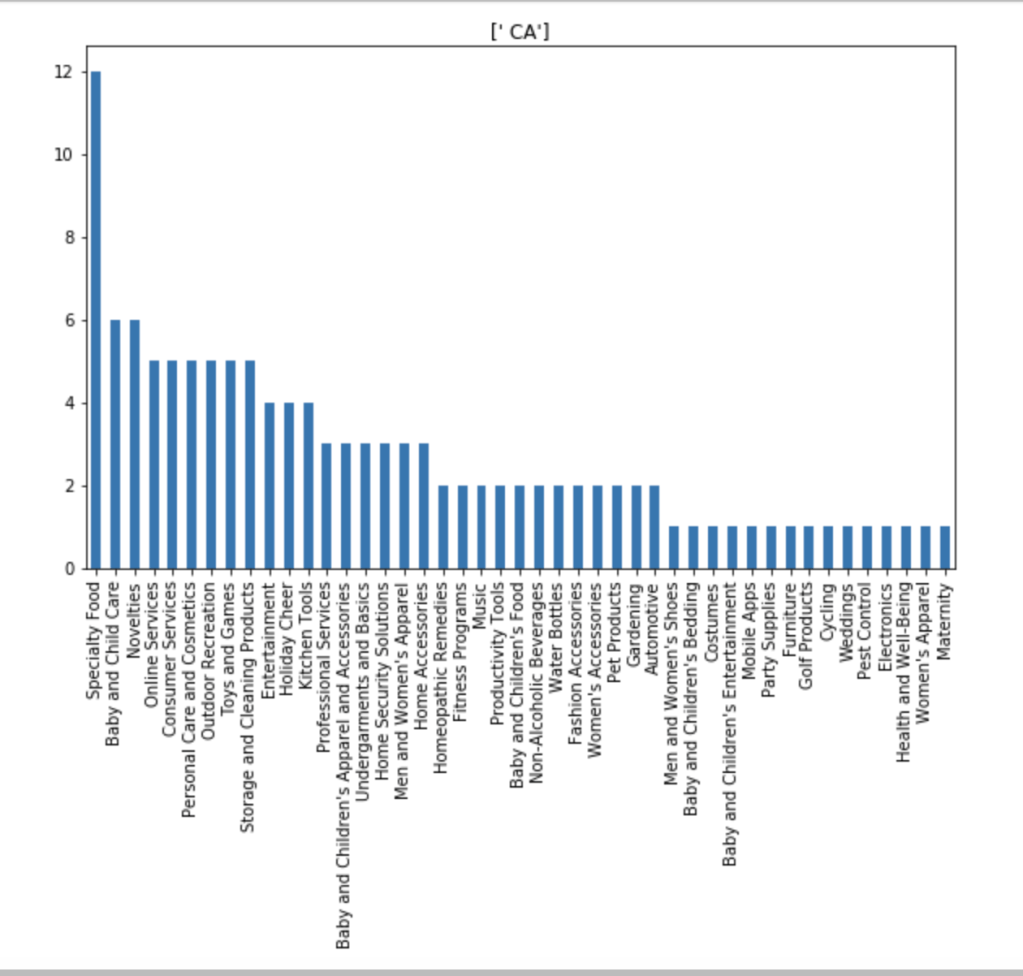
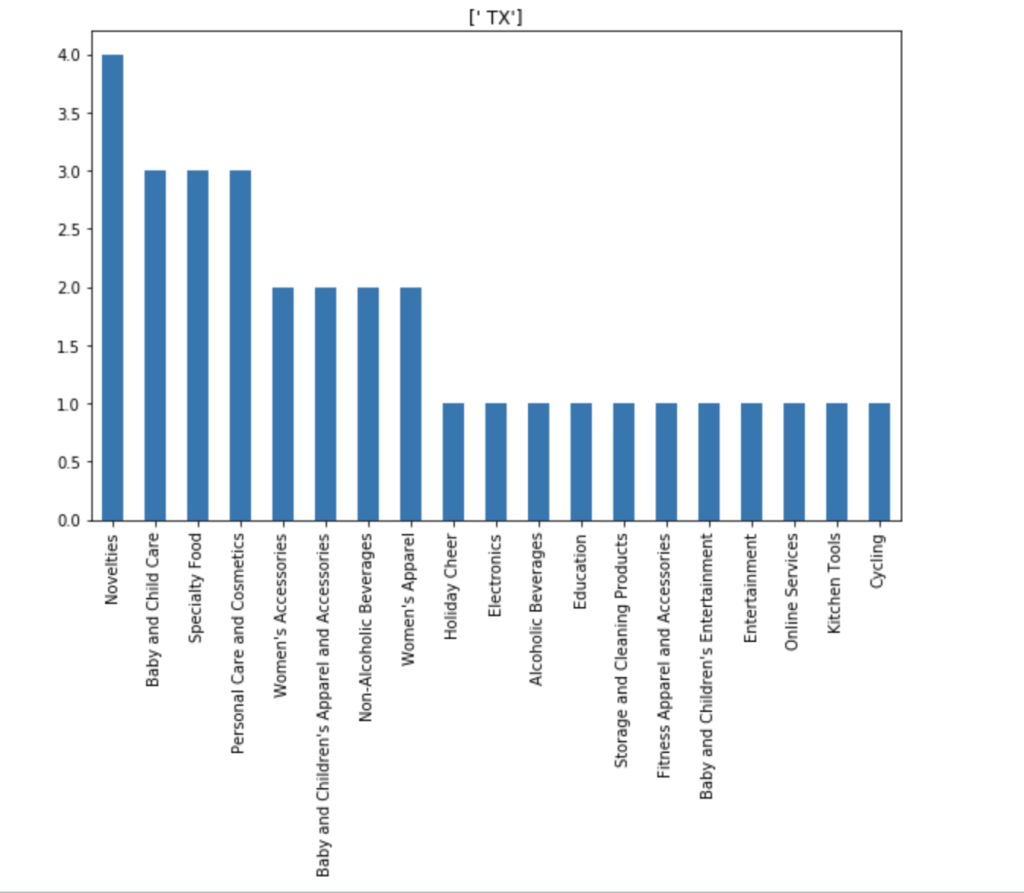
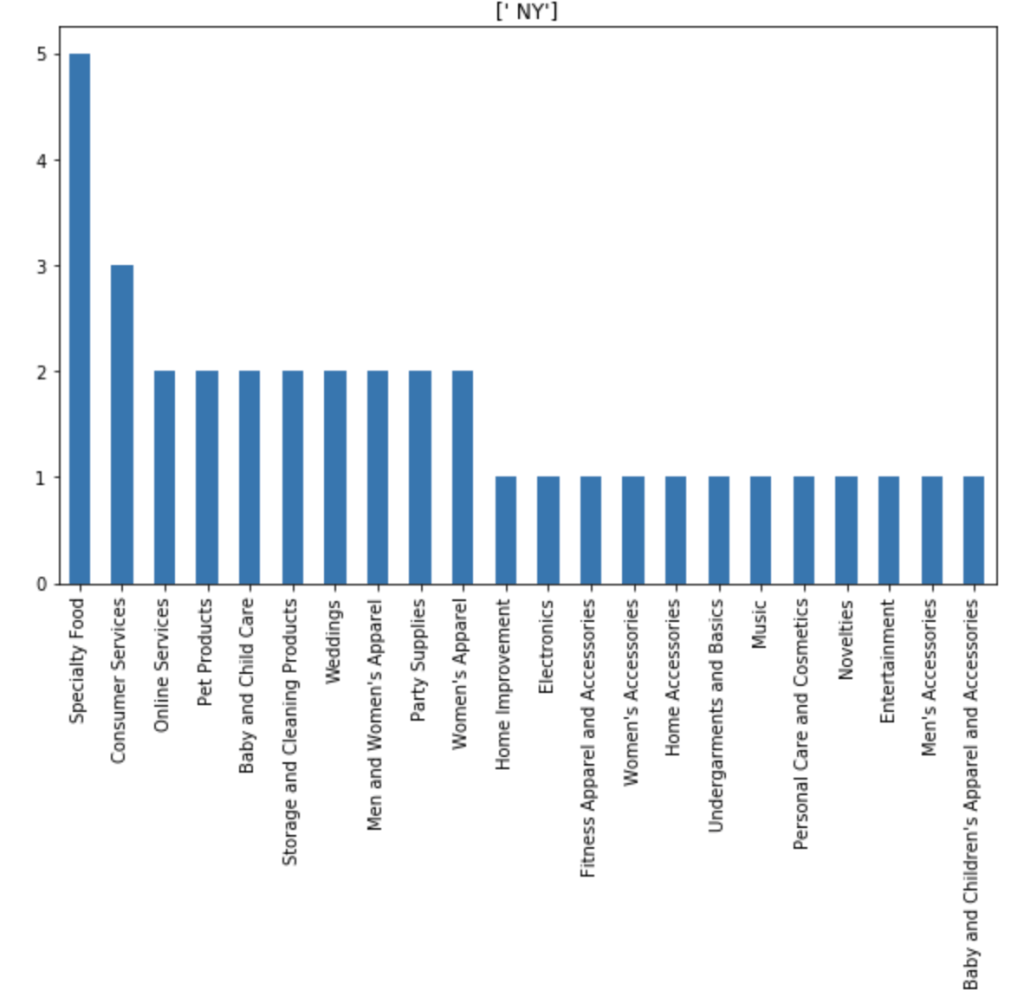
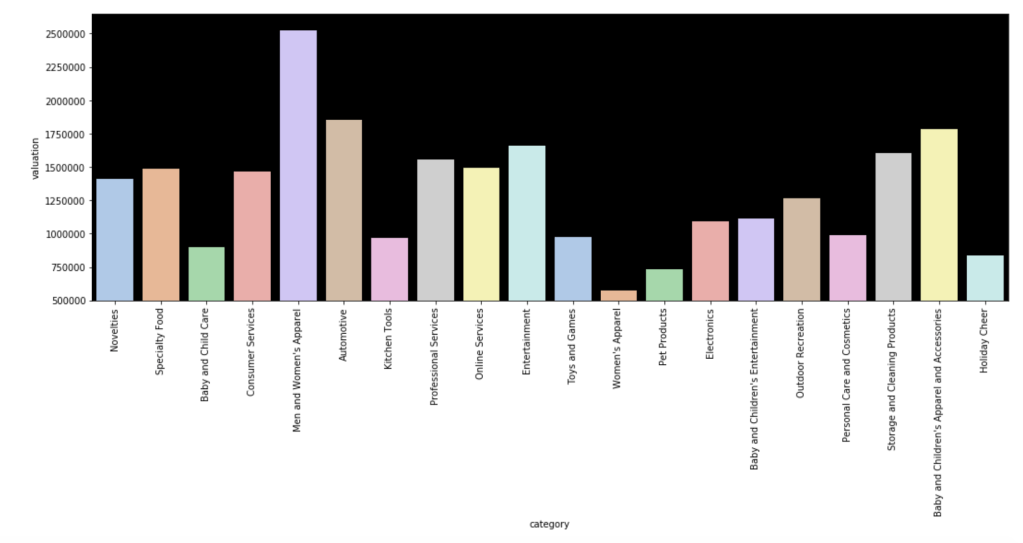
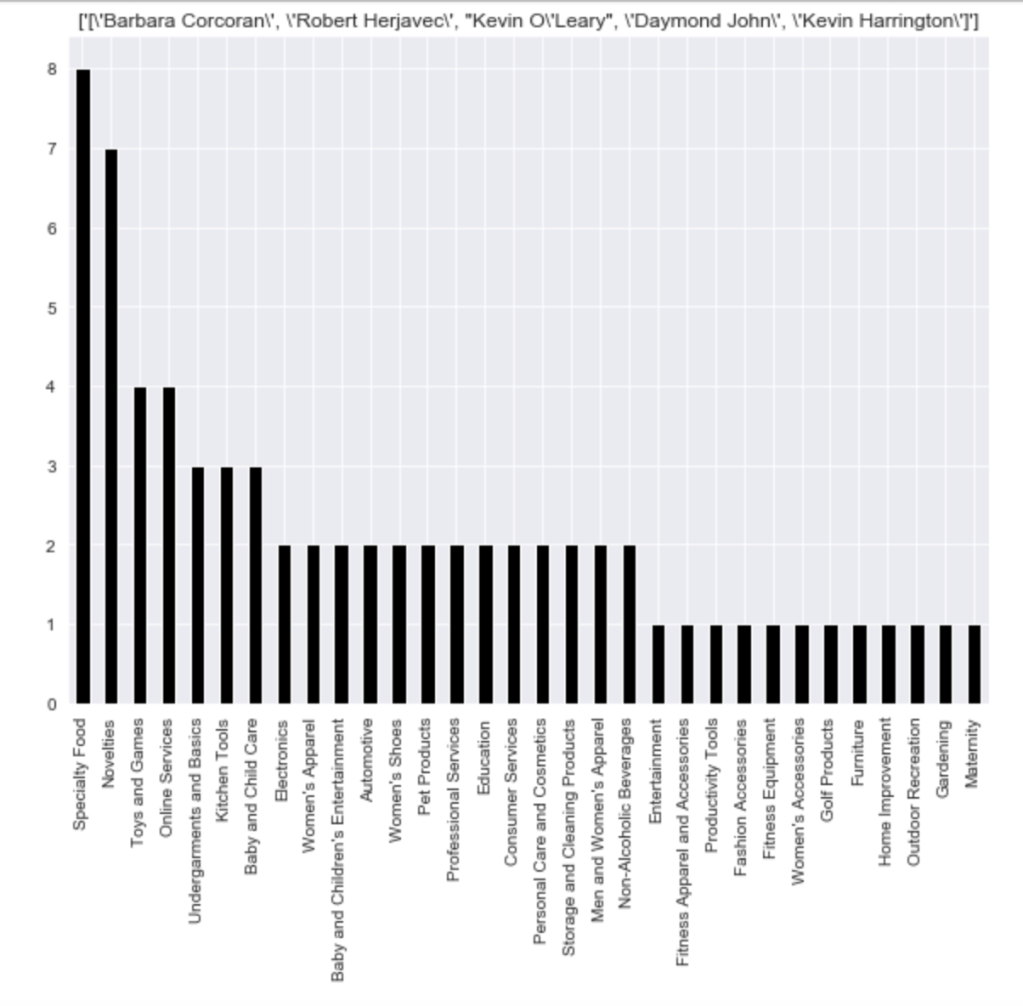
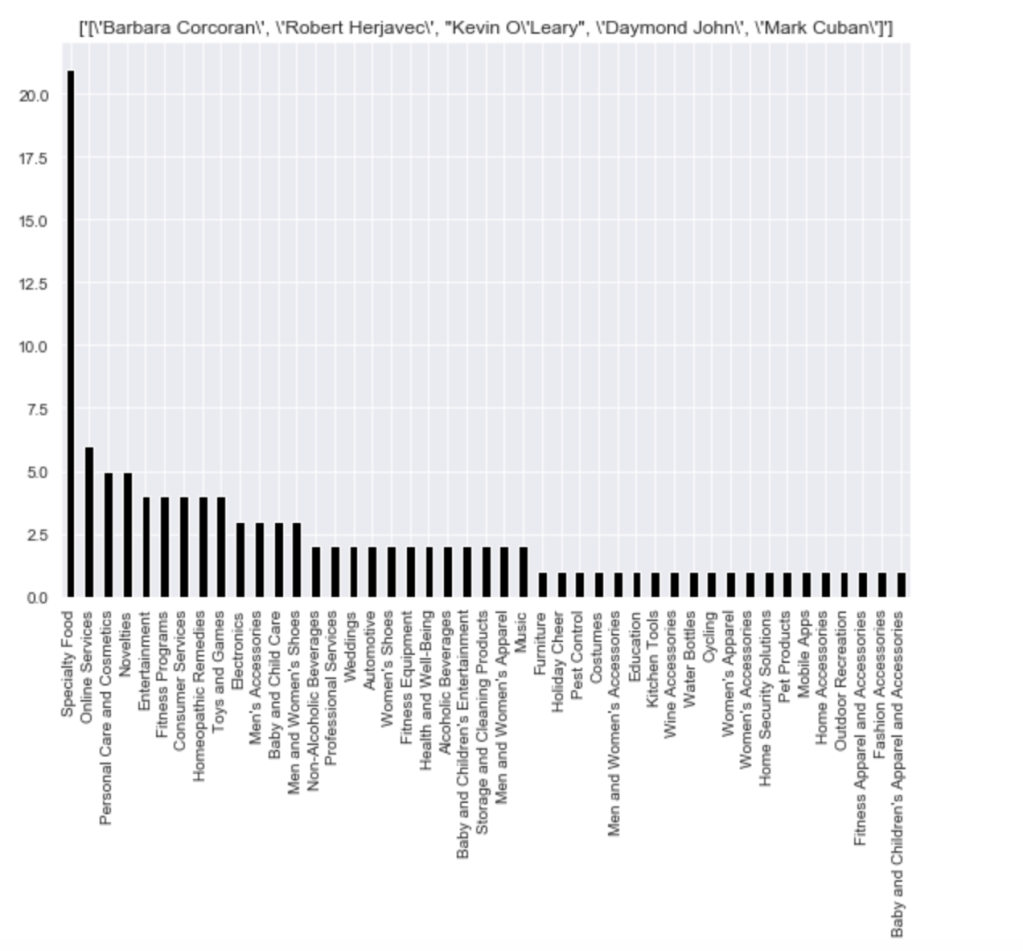
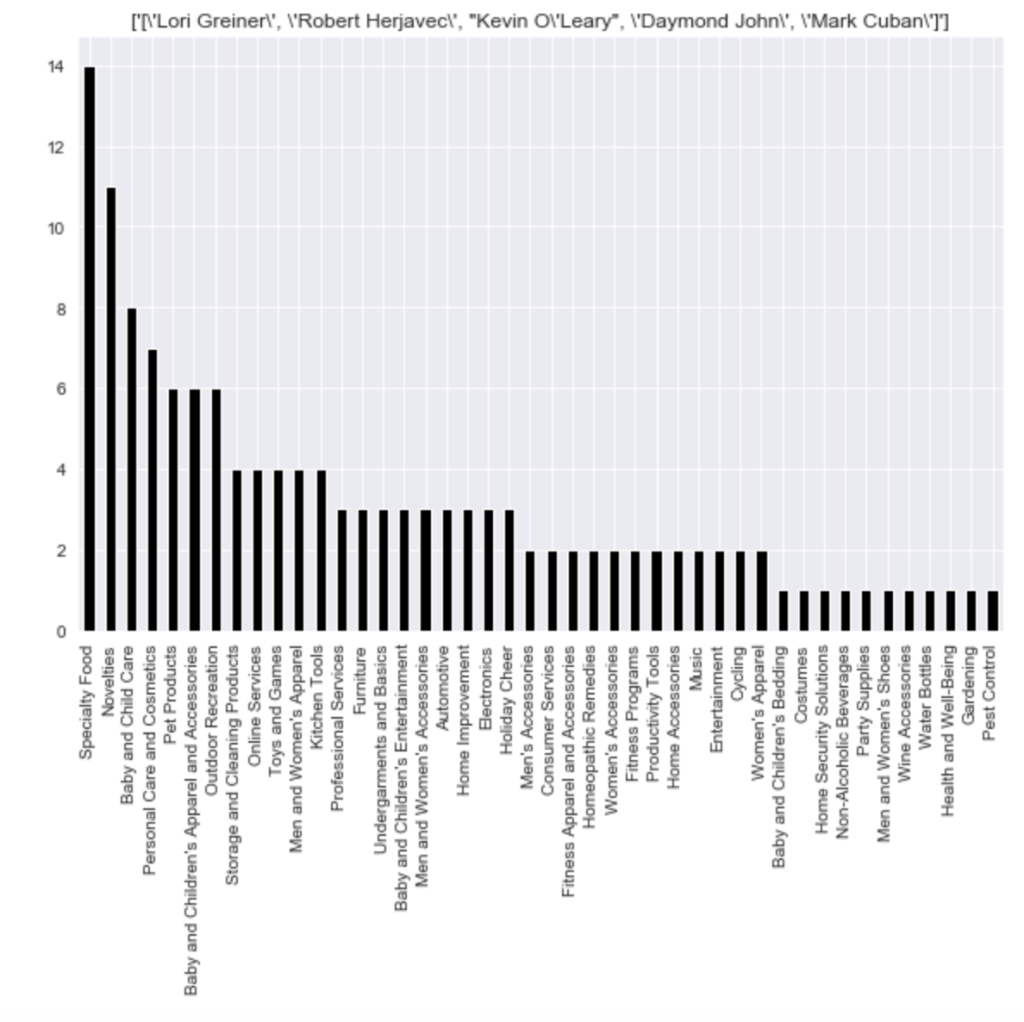
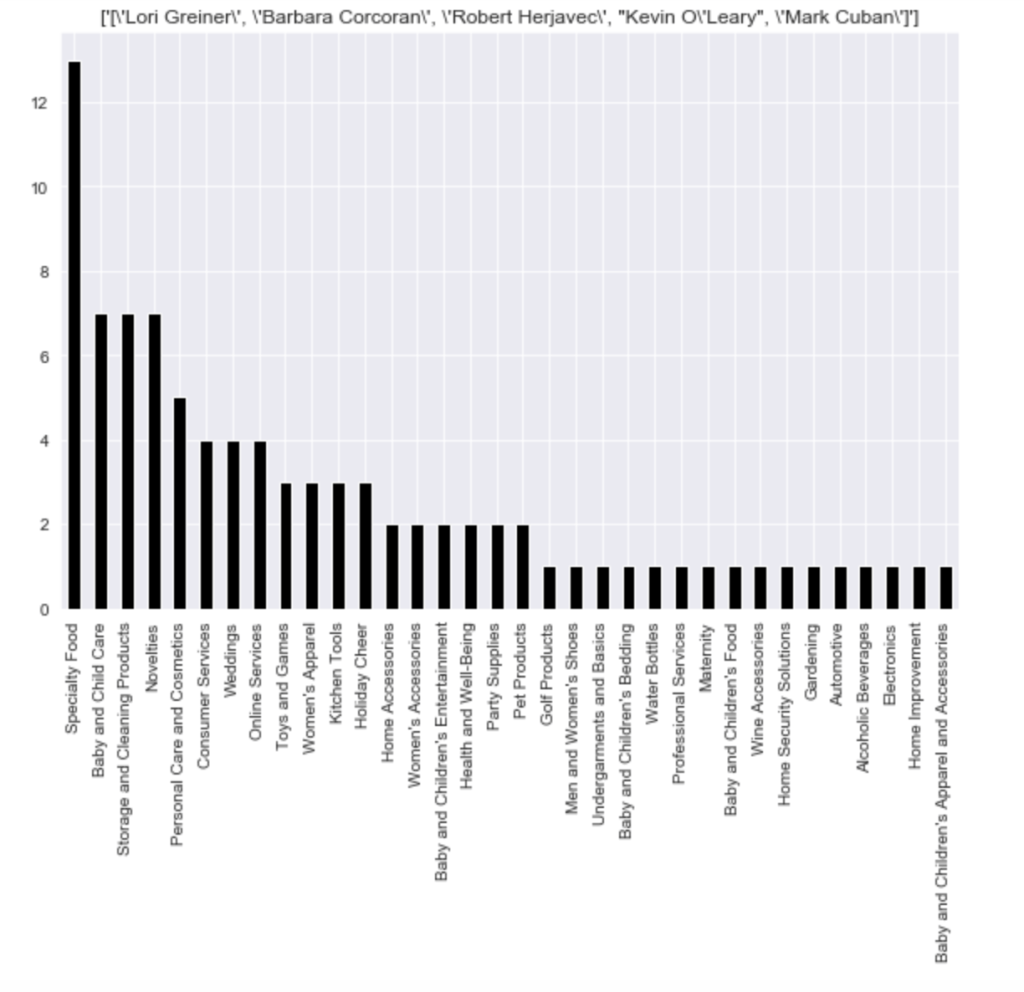
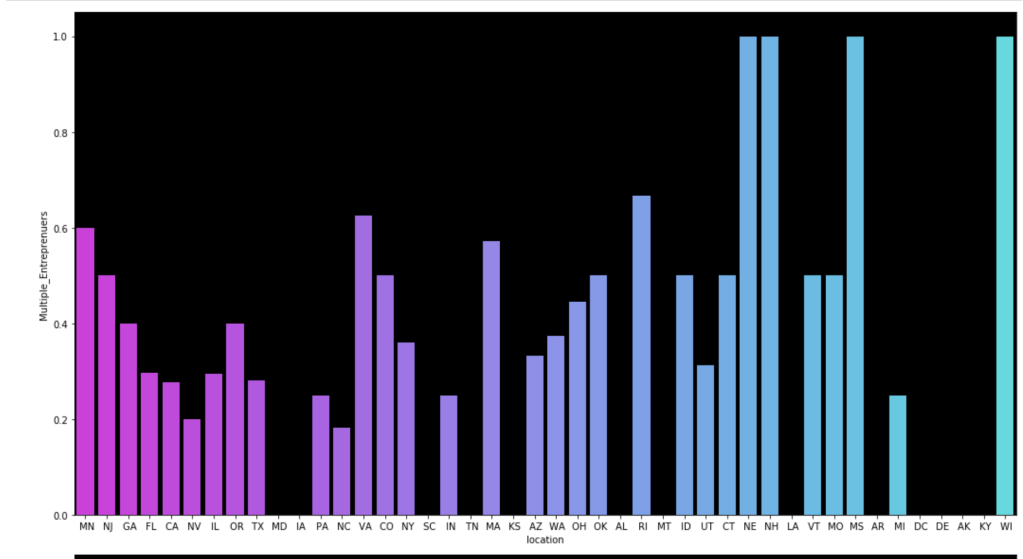
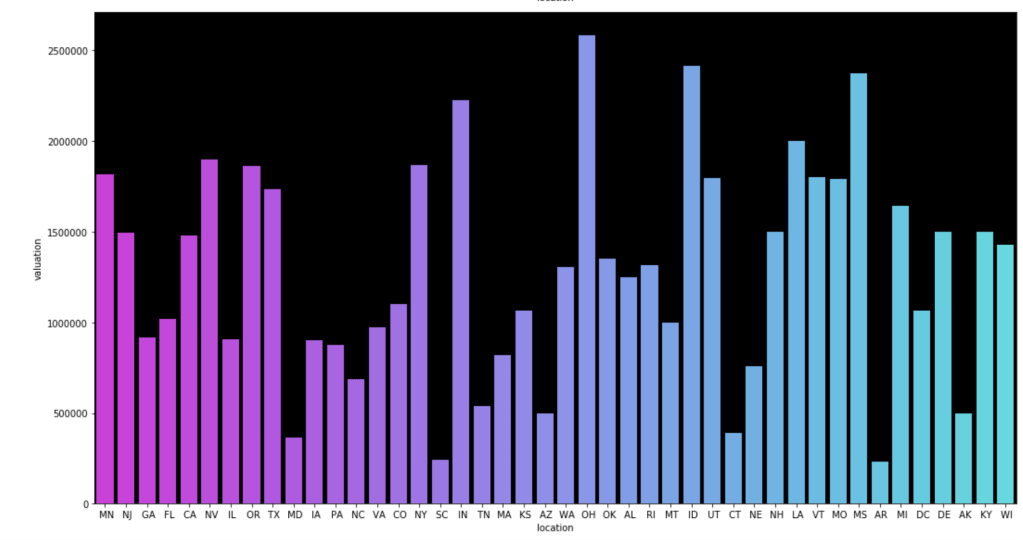
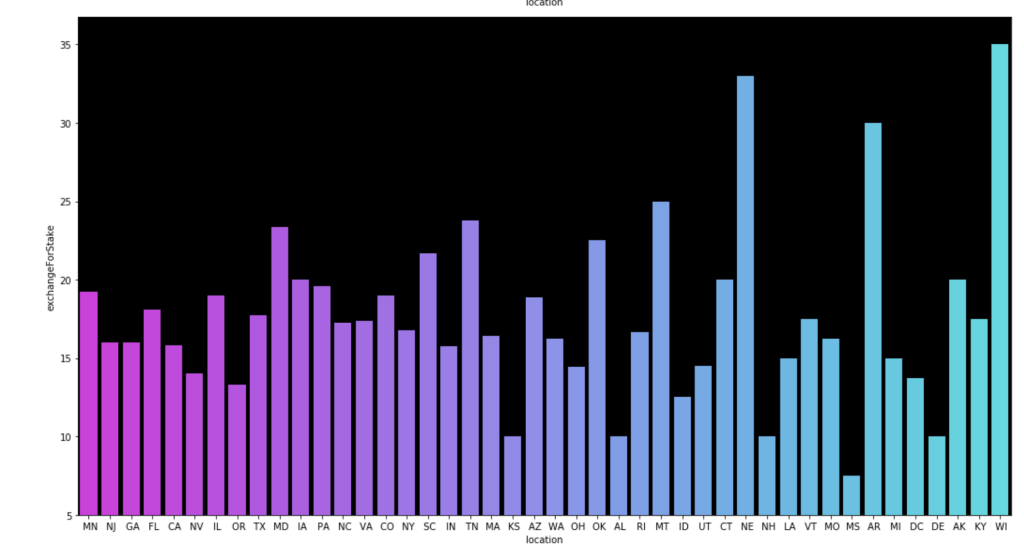
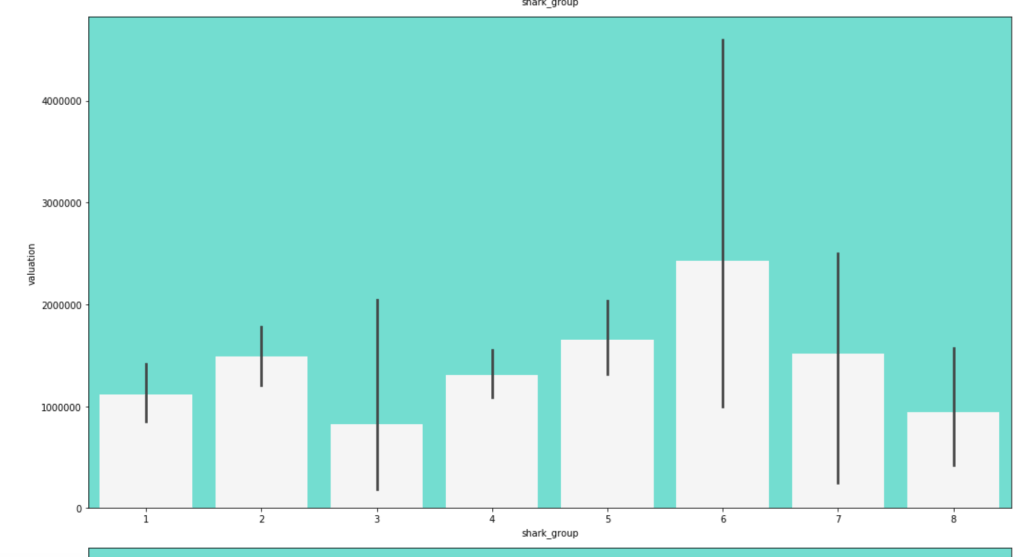
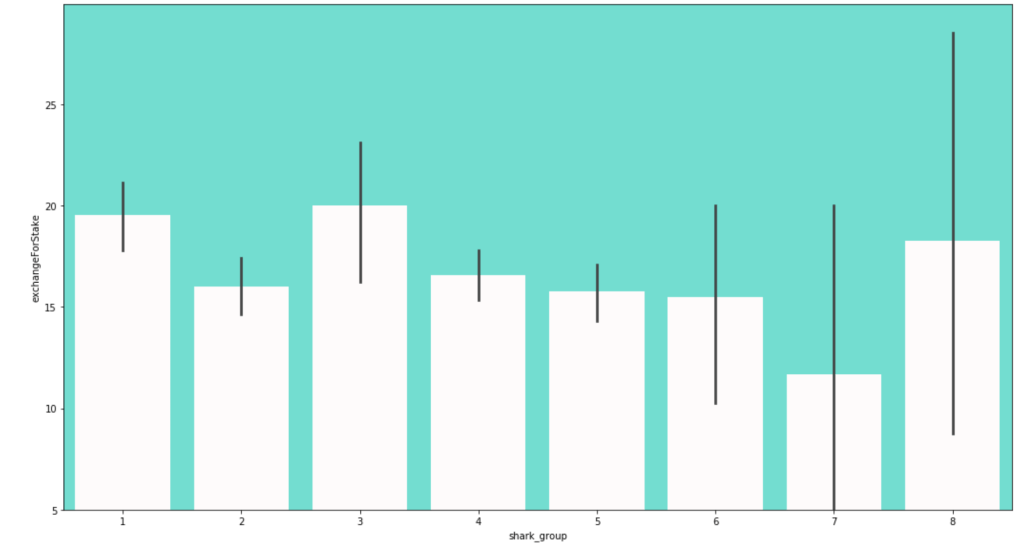
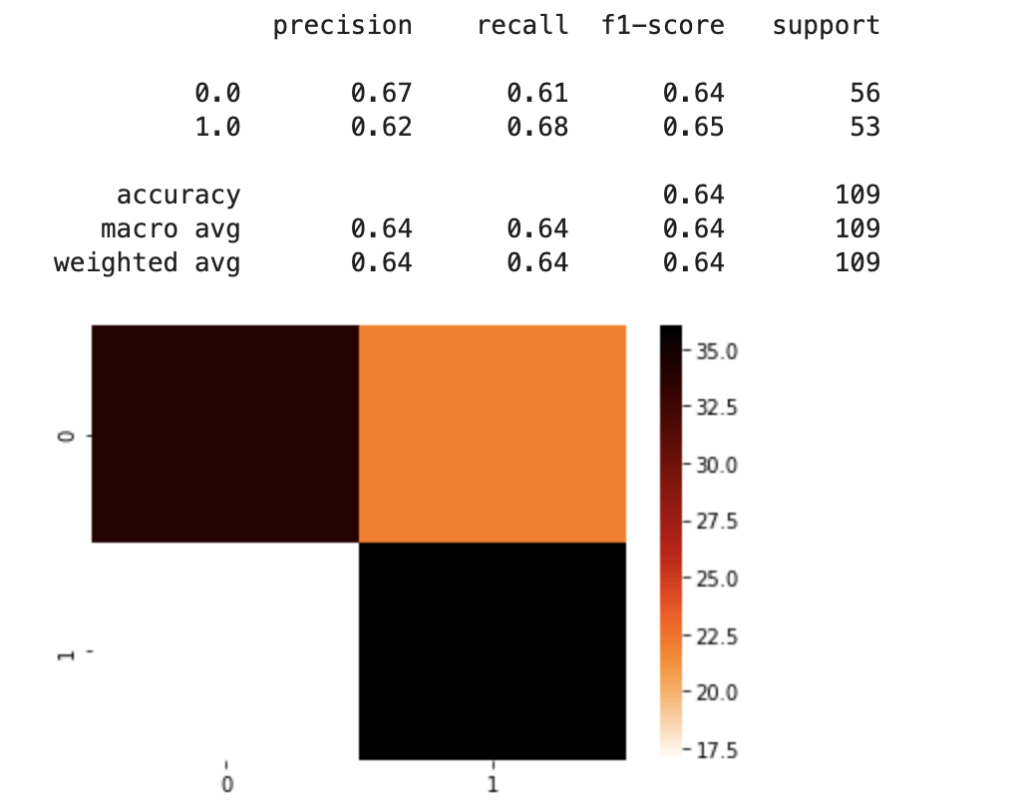
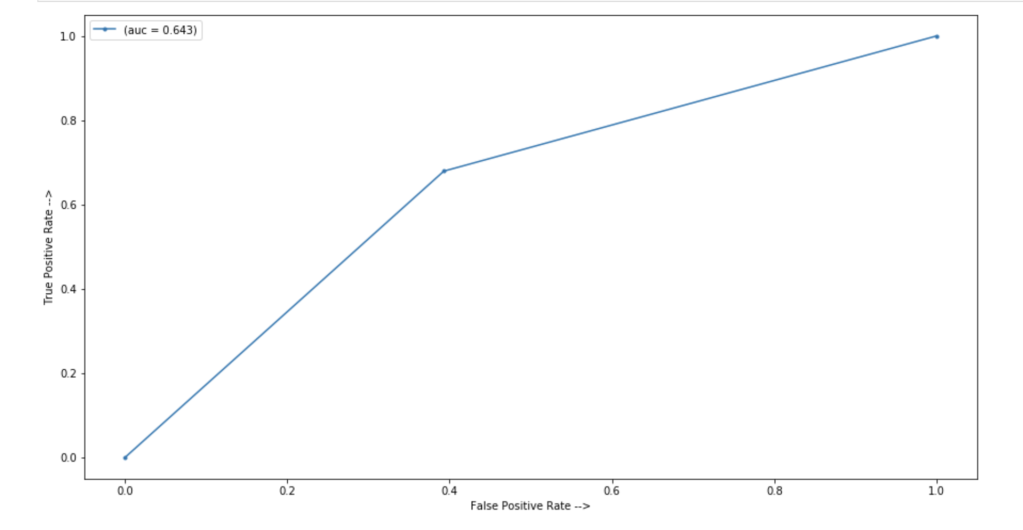
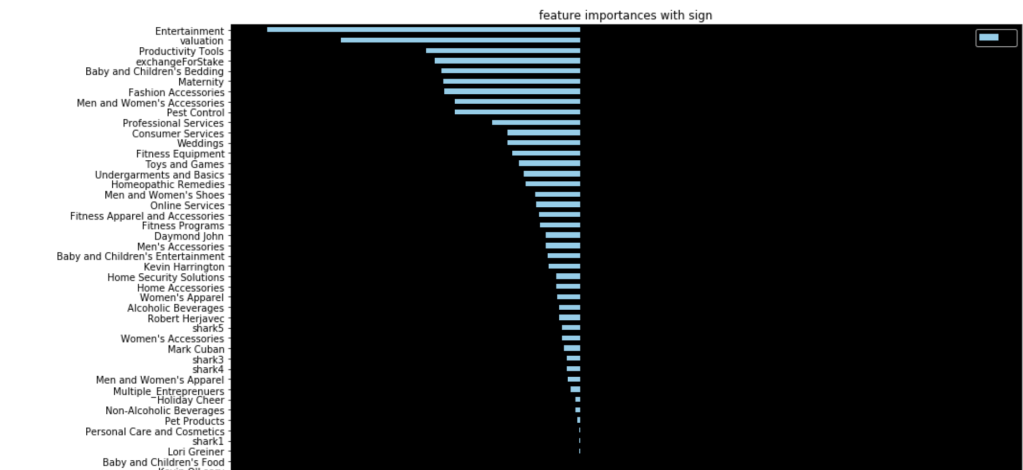
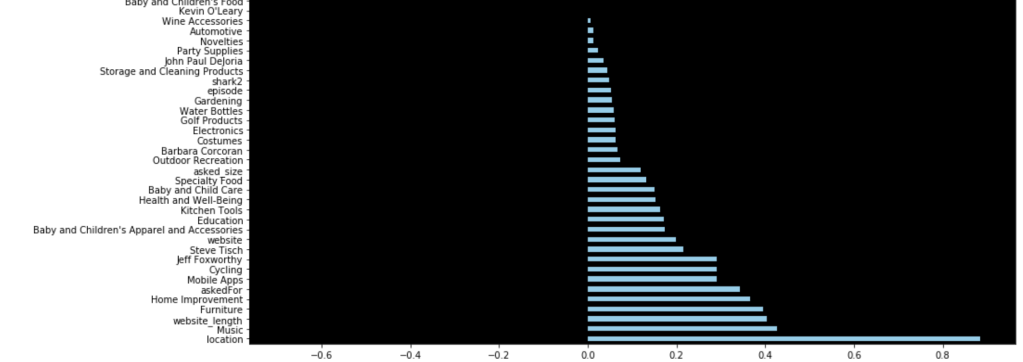
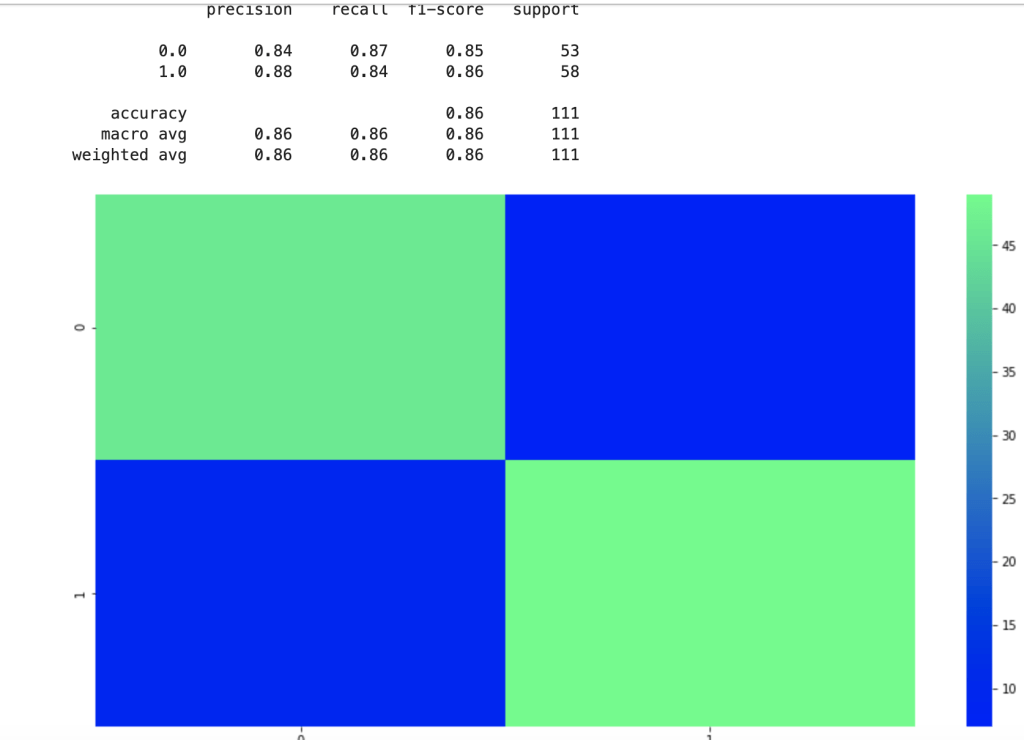
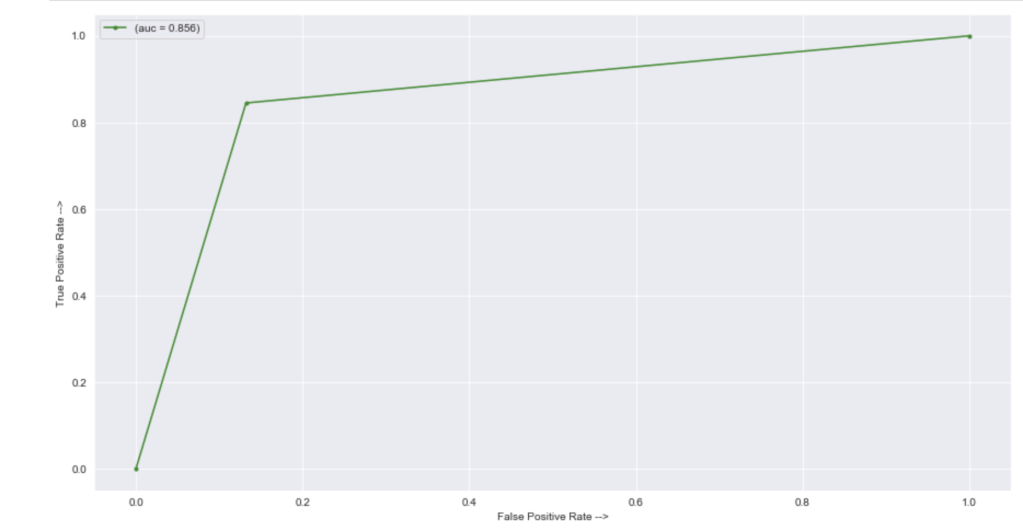
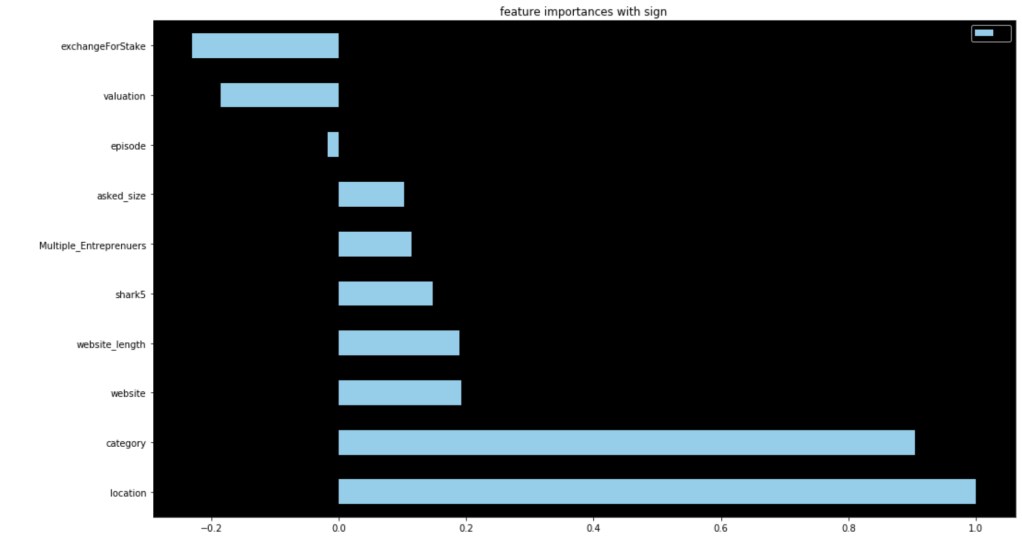

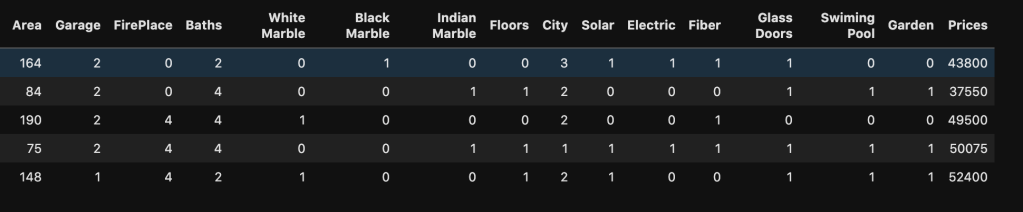
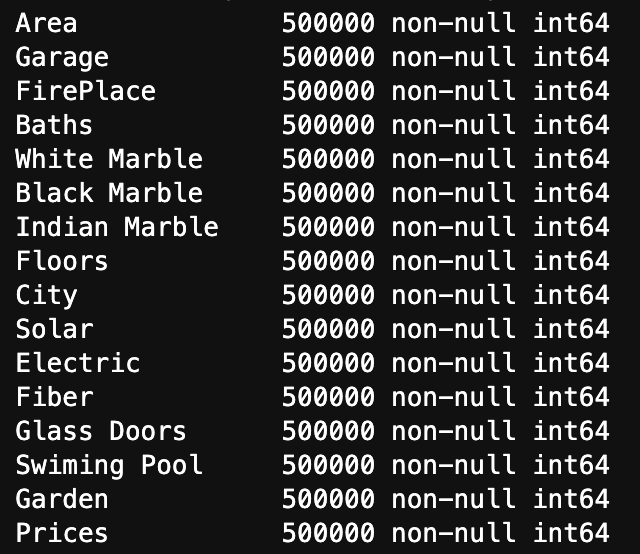
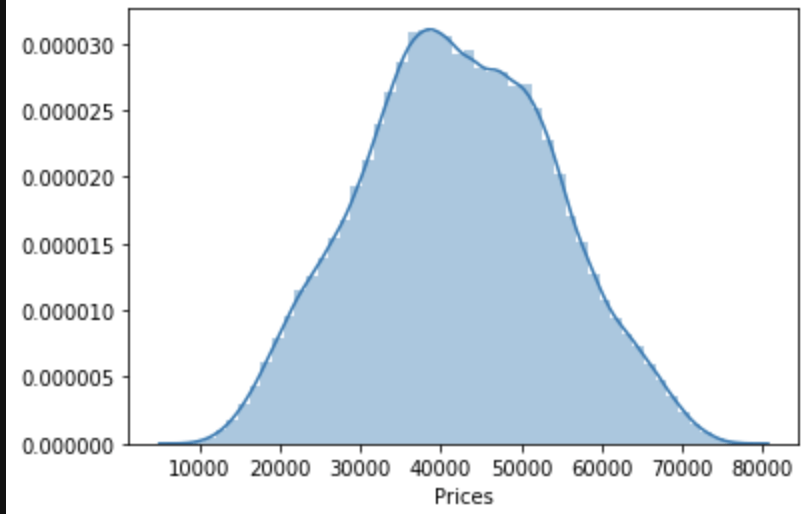
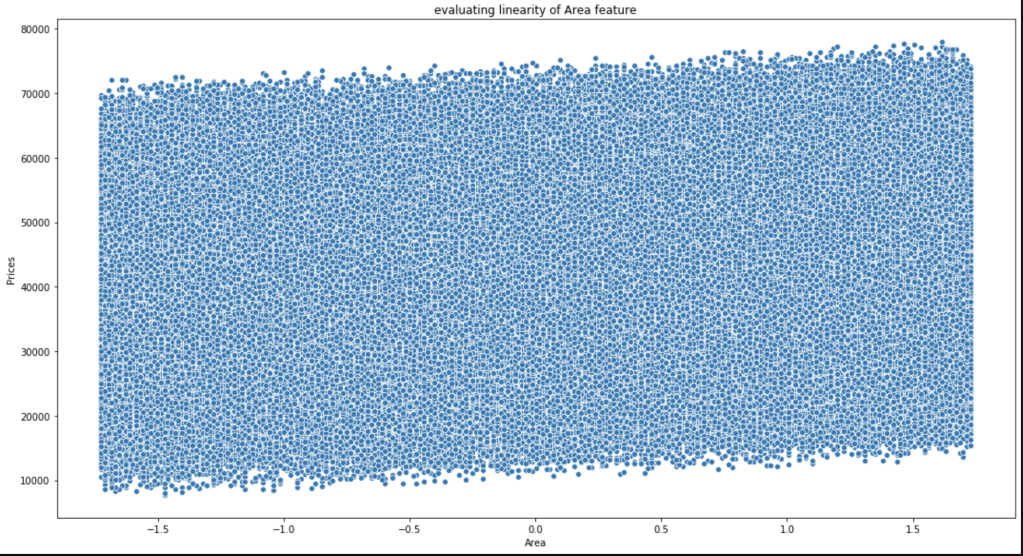
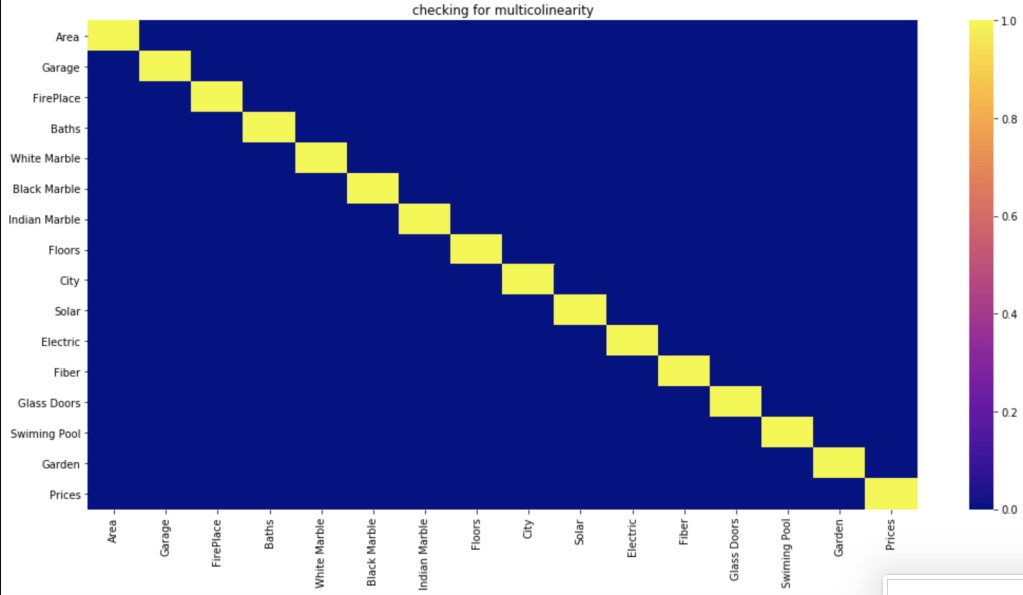

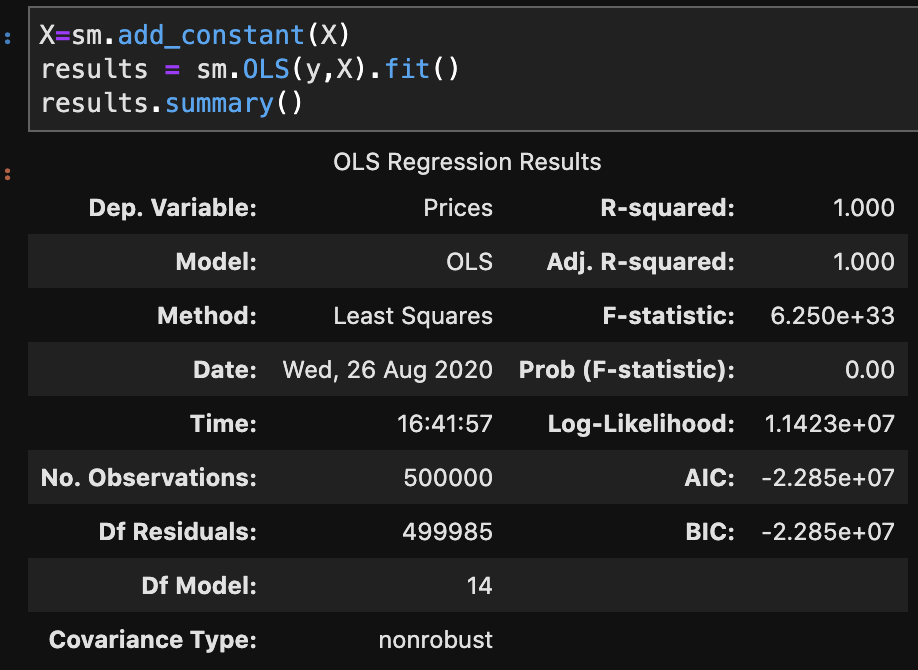
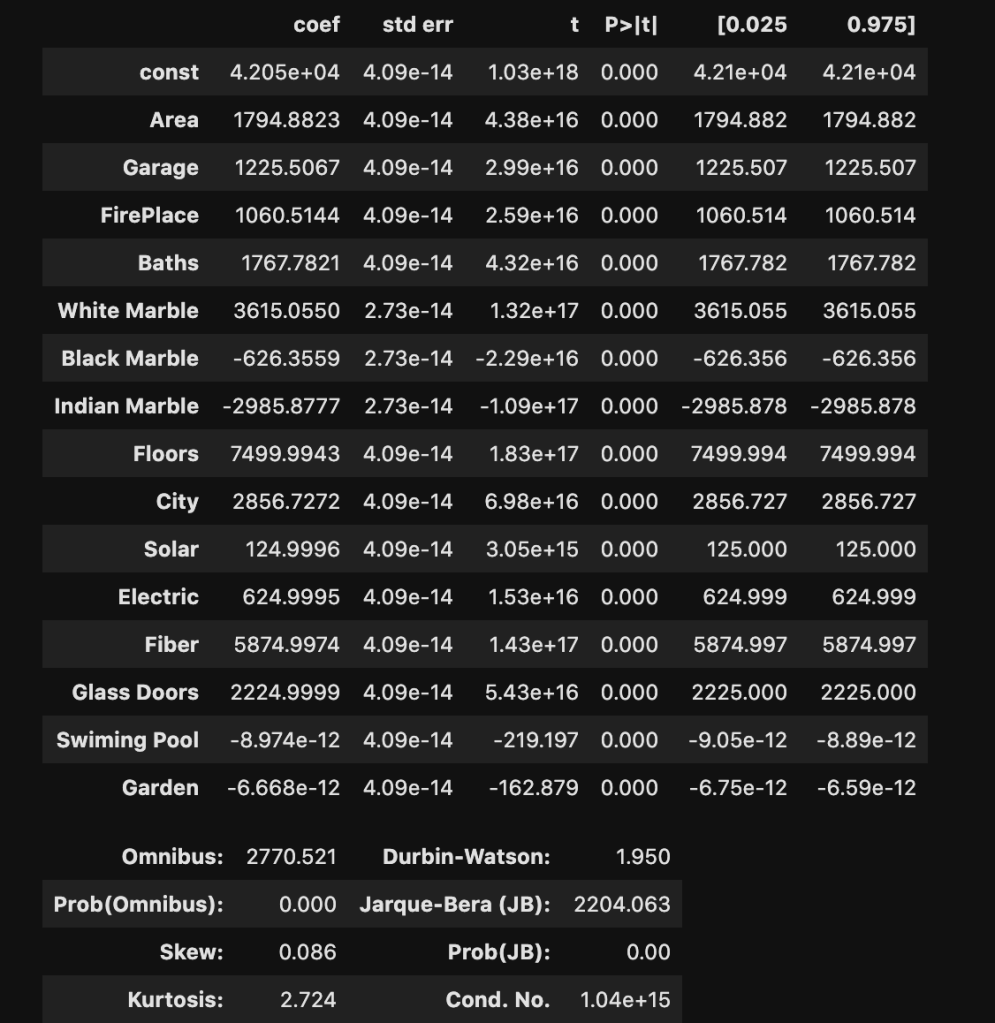
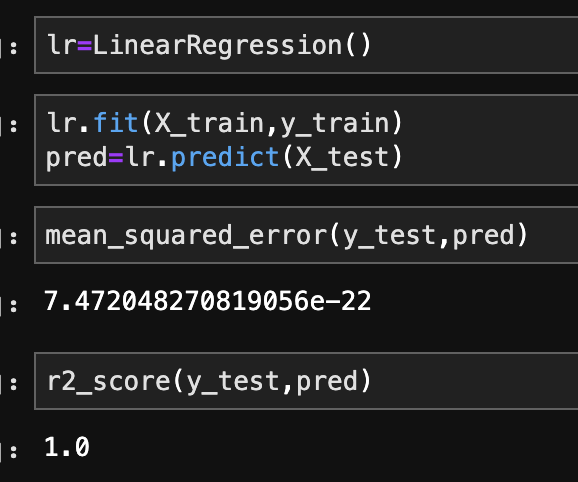
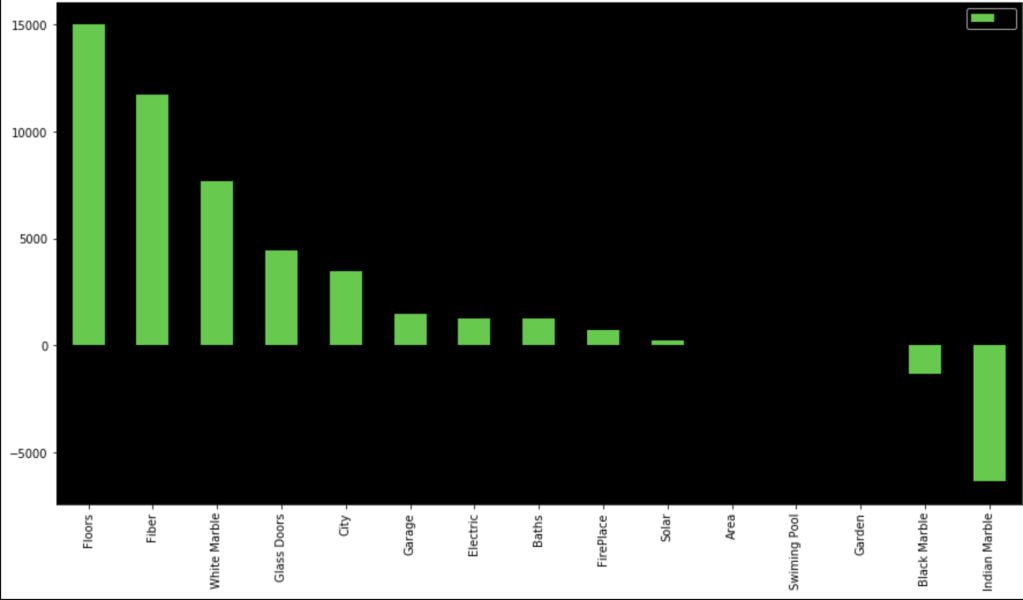

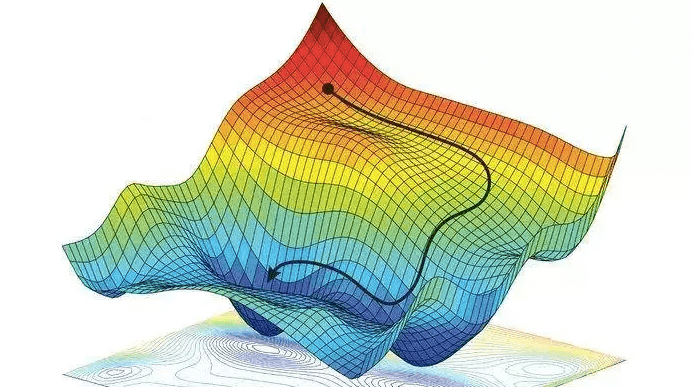
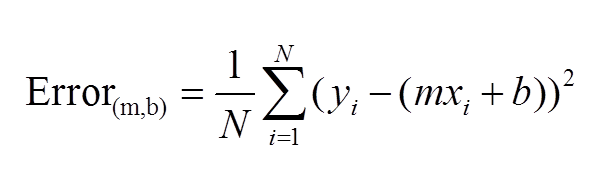
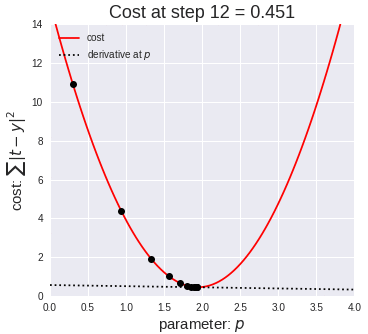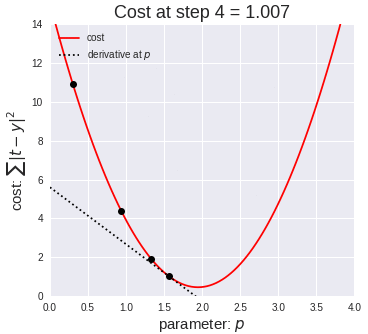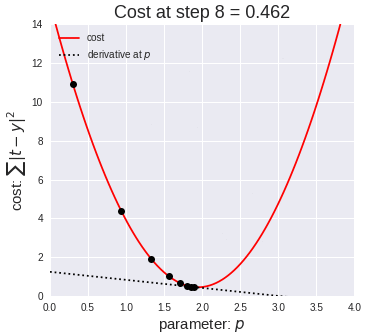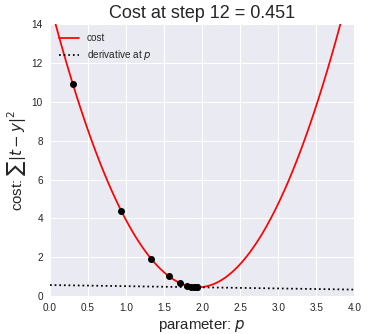

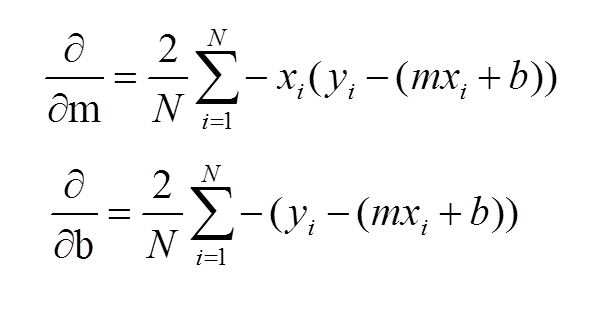



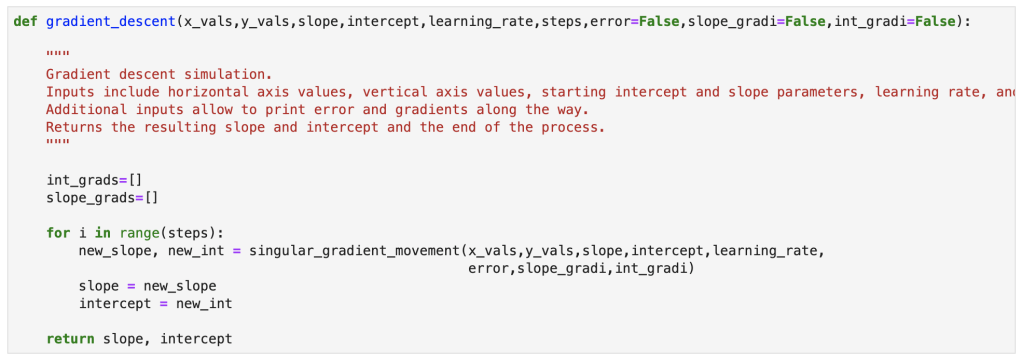


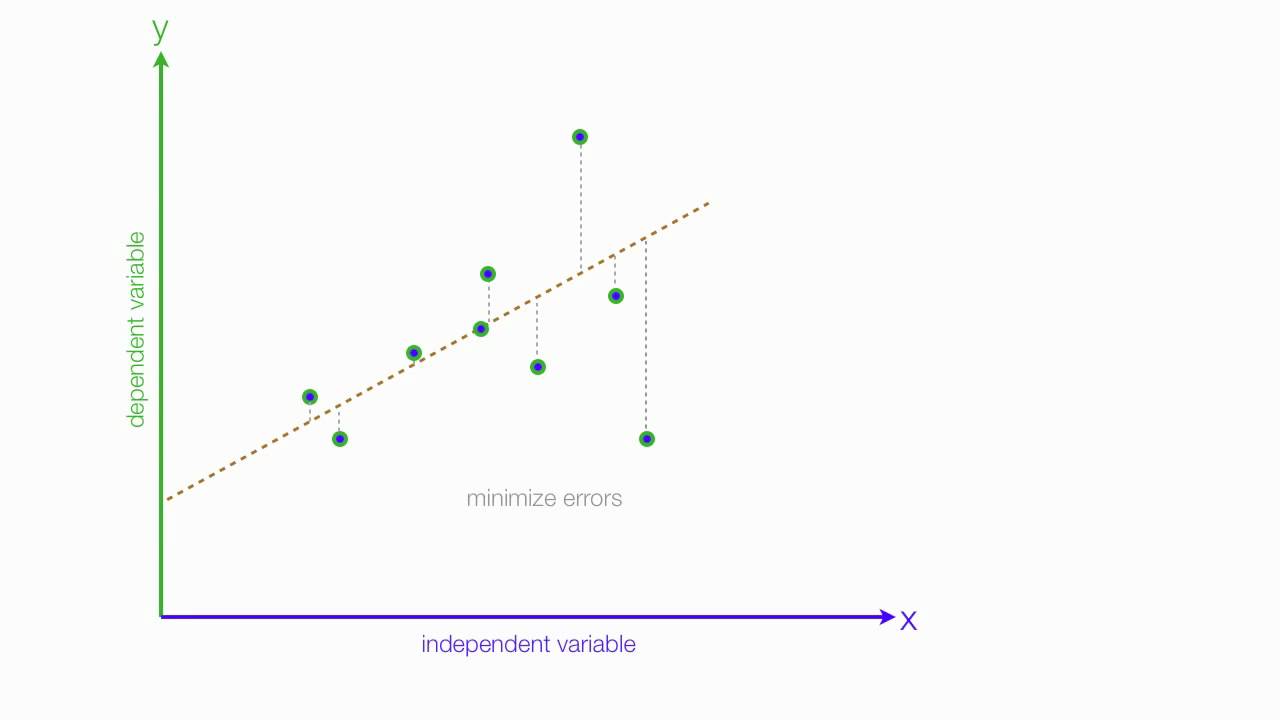

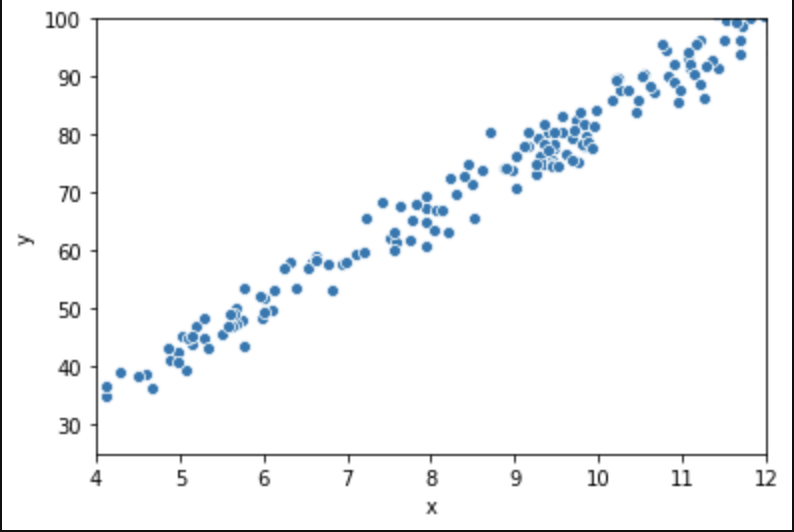
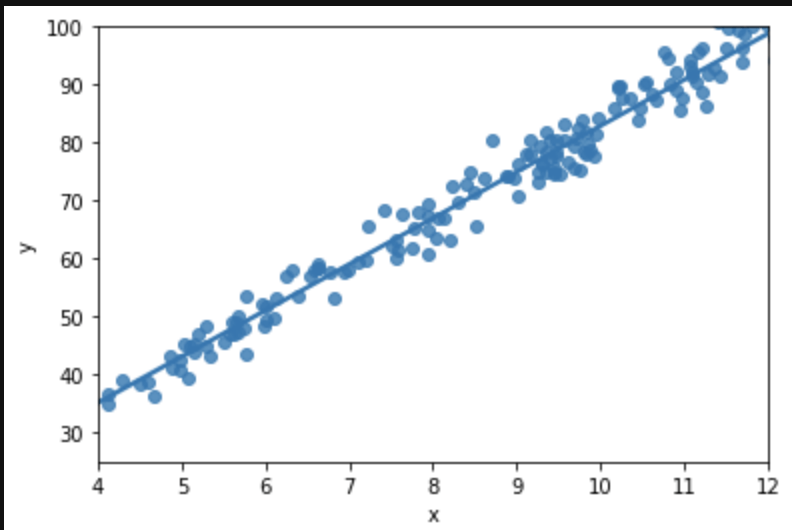
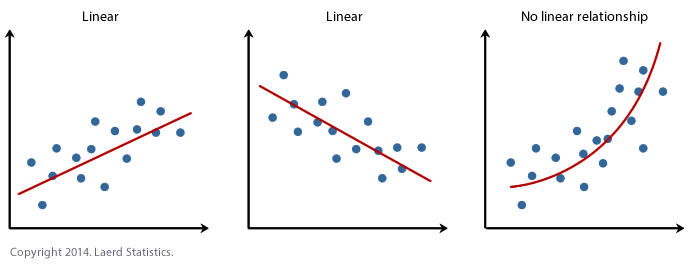

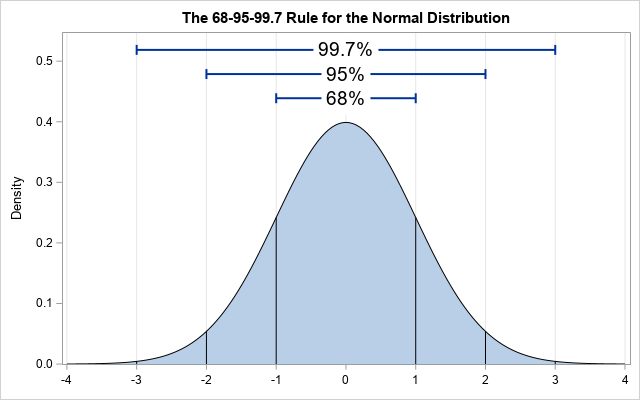
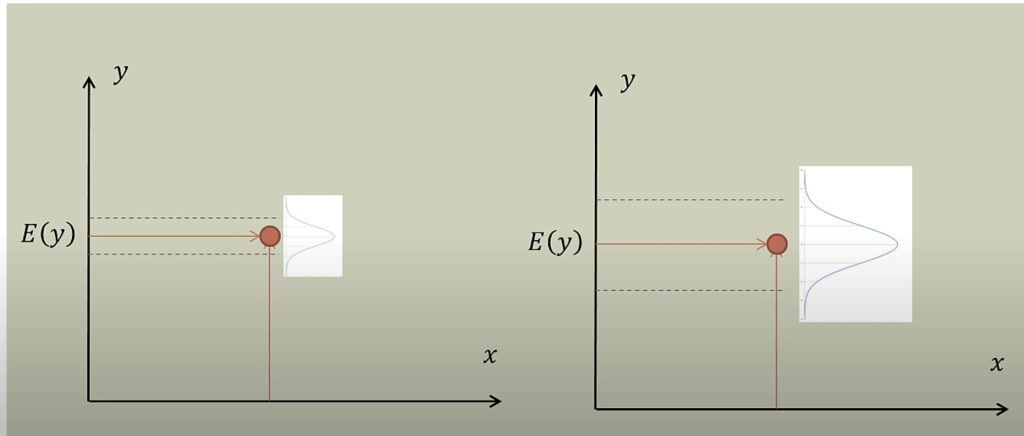
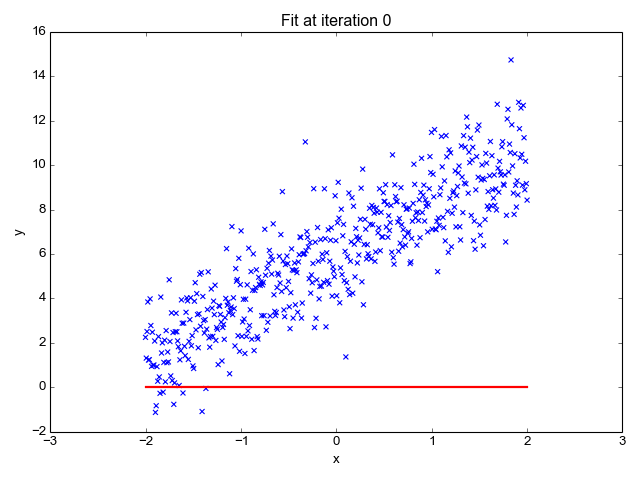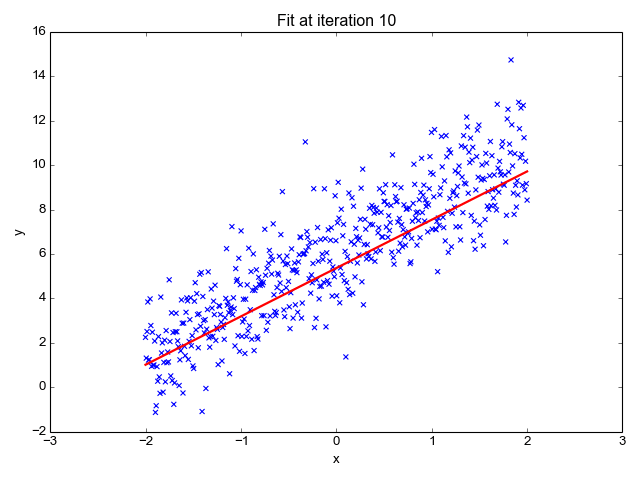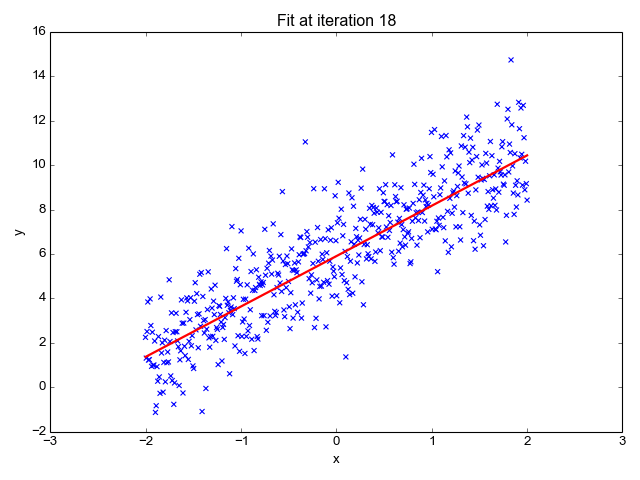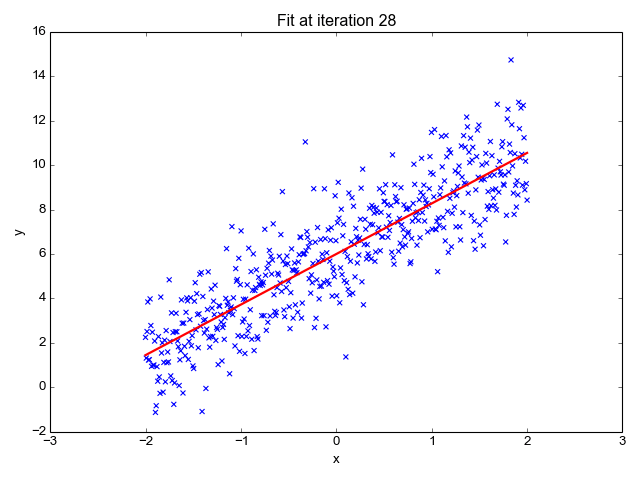

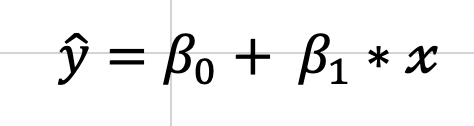
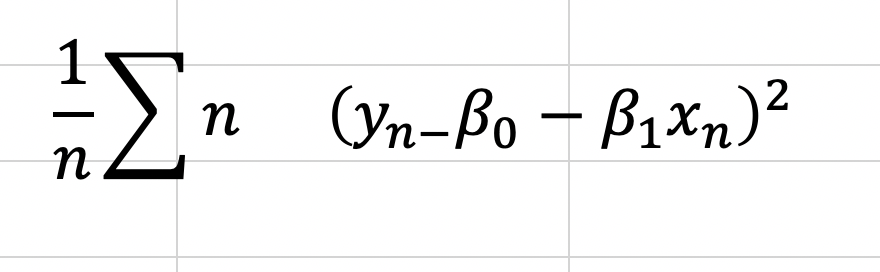
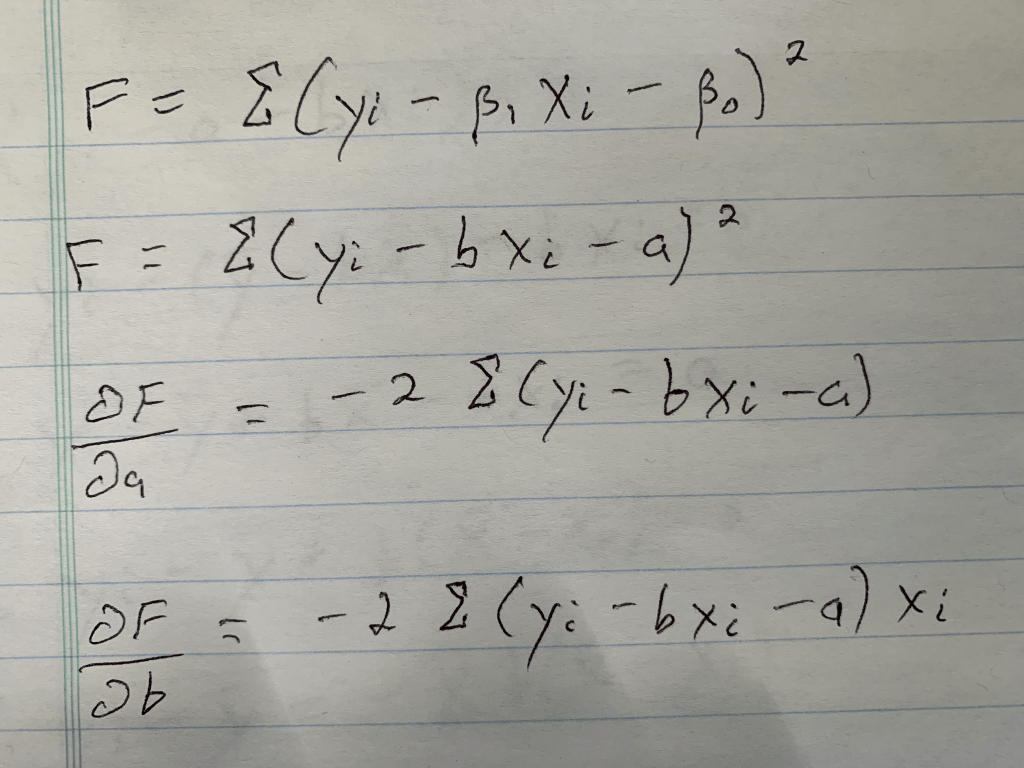

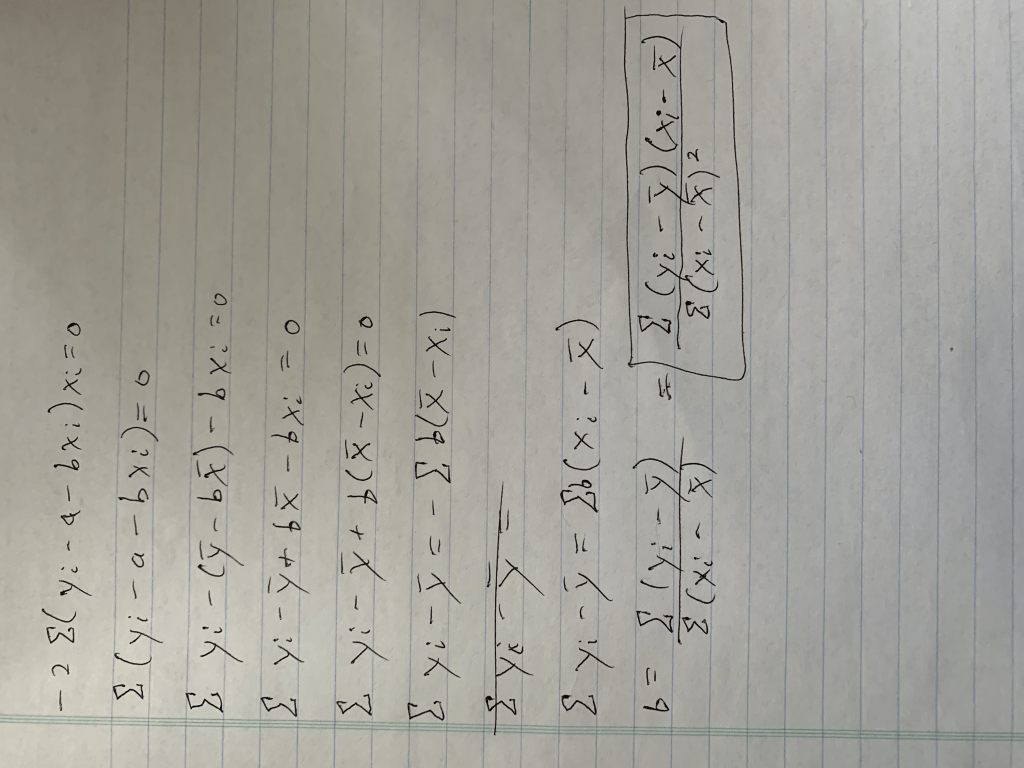
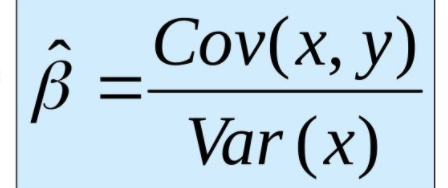
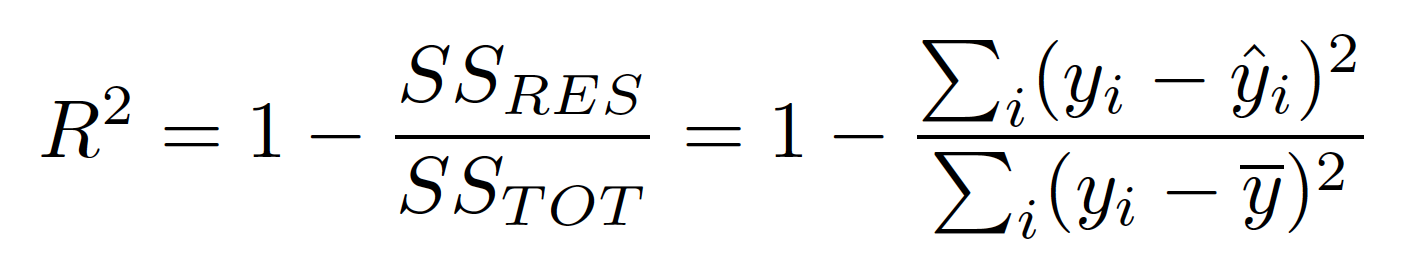



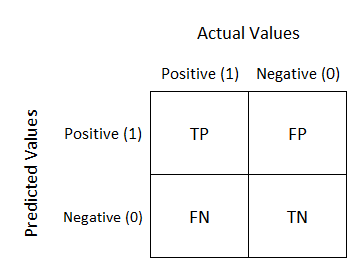
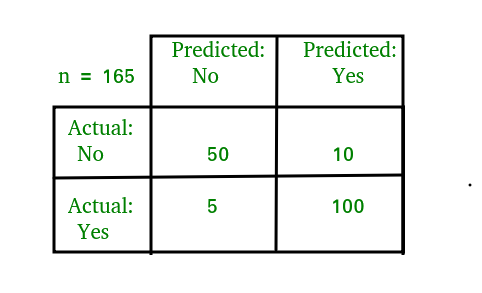
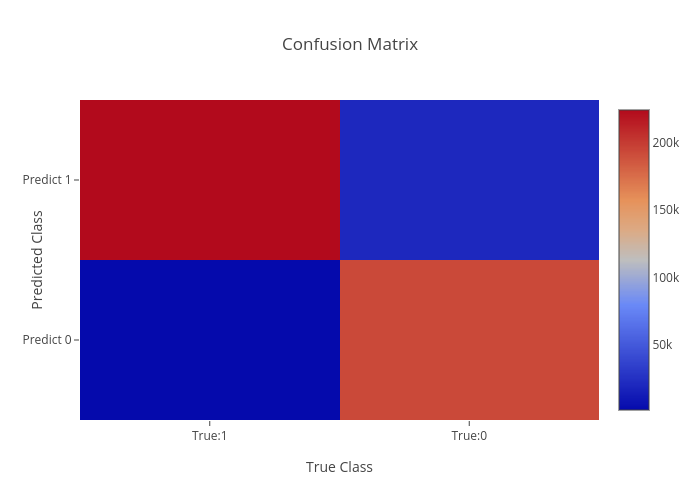
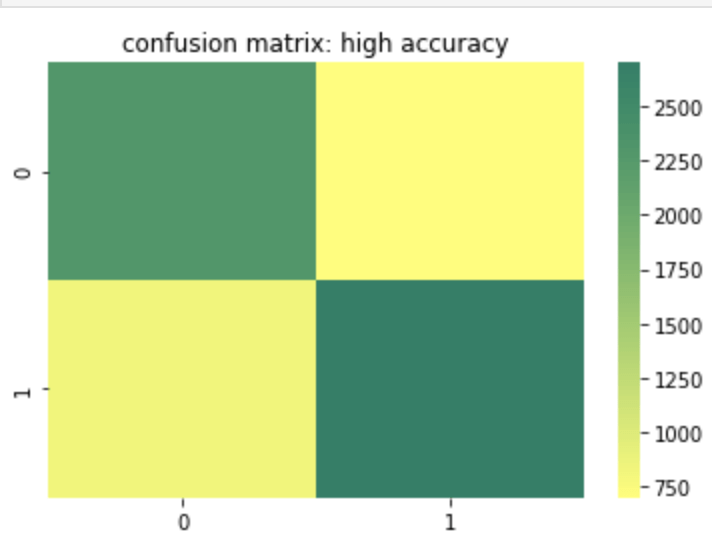
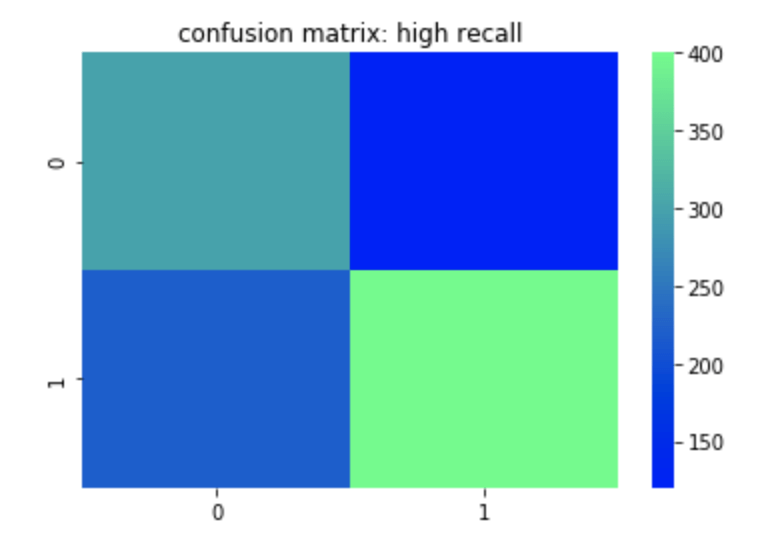
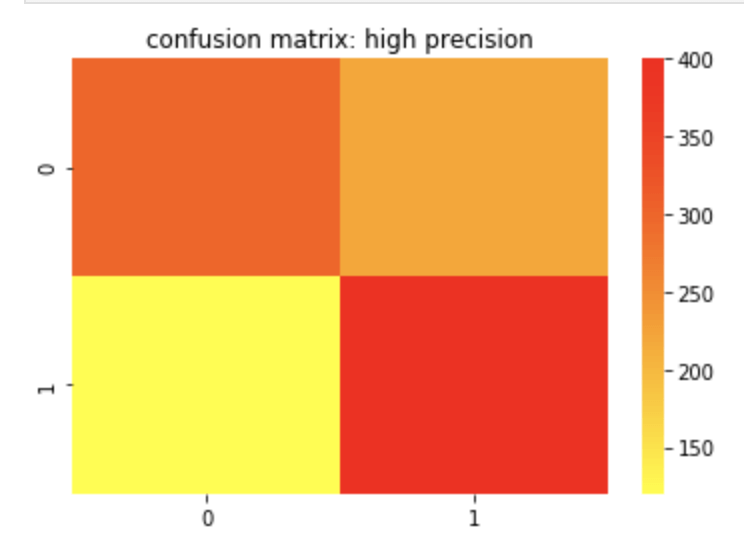




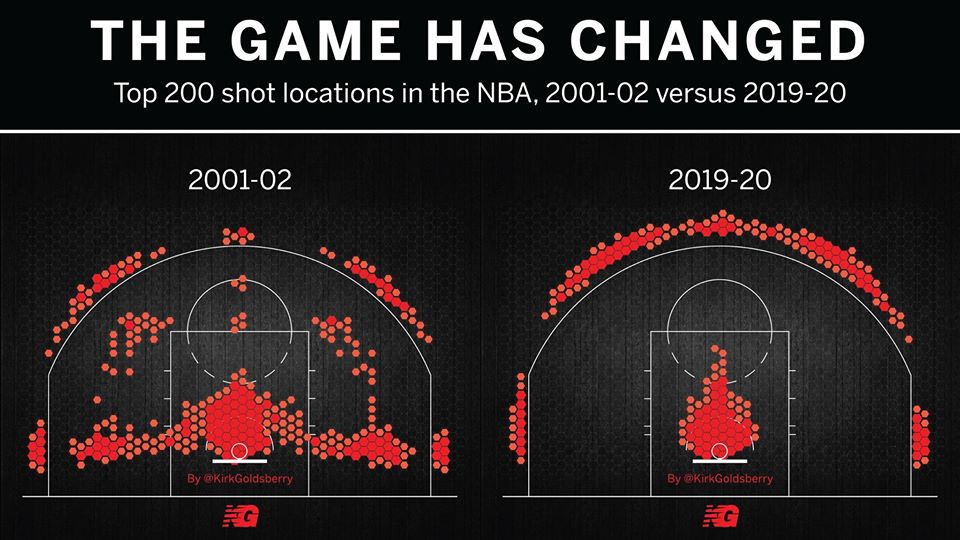
:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/19412592/swish_4_.png)
:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/19412589/swish_3_.png)