Learning the basics of a useful AutoML library

Introduction
Thank you for visiting my blog today!
Recently, I was introduced to an interesting library geared toward building fast and accurate machine learning models using a library called AutoGluon. I don’t claim credit for any of the fancy backend code or functionality. However, I would like to use this blog as an opportunity to quickly introduce this library to anyone (and I imagine that includes most people who are data scientists) and show a quick modeling process. A word I used twice in the past sentence was “quick.” As we will see, that is the one of the best parts of AutoGluon.
Basic Machine Learning Model
In order to evaluate whether AutoGluon is of any interest to me (or my readers), I’d like to first discuss what I normally want from an ML model. For me, outside of things like EDA, hypothesis testing, or data engineering, I am mainly looking for two things at the end of the day; I want the best possible model in terms of accuracy (or recall or precision) and also want to look at feature importances as that is often where the interesting story lies. How we set ourselves up to have a good model that can accomplish these two tasks in the best way possible is another story for another time and frankly it would be impossible to tell that entire story in just one blog.
An autogluon Model Walkthrough
So let’s see this in action. I will link the documentation here before I begin: (https://autogluon.mxnet.io/). Feel free to check it out. Like I said, I’m just here today to share this library. First things first though: my data concerns wine quality using ten predictive features. These features are citric acid, volatile acidity, chlorides, density, pH level, alcohol level, sulphates, residual sugar, free sulfur dioxide, and residual sulfur dioxide. It can be found at (https://www.kaggle.com/uciml/red-wine-quality-cortez-et-al-2009). This data set actually appears in my last blog on decision trees.
Ok, so the next couple lines are fairly standard procedure, but I will explain them:

Basically, I am loading all my functions, loading my data, and splitting my data into a set for training a model and a set for validating a model.
Here comes the fun stuff:

So this looks pretty familiar to a data scientist. We are fitting a model on data and passing the target variable to know what is being predicted. Here is some of the output:
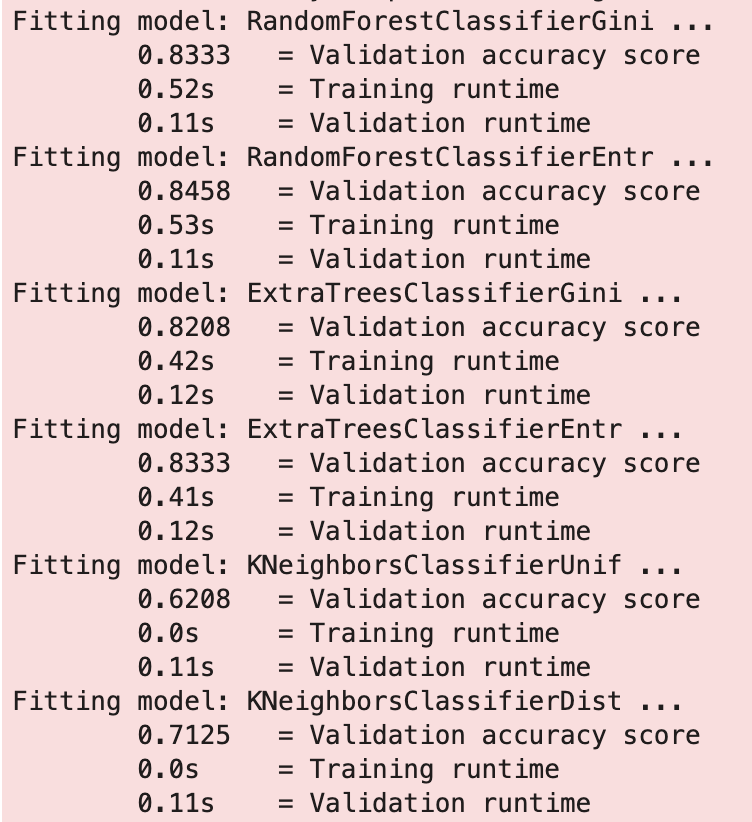
That was fast. We also what models worked best.
Now let’s introduce new data:

Output:


Whoa is right, it looks we just entered The Matrix. Ok… this is really not that complex, so let’s just take one more step:

Output:
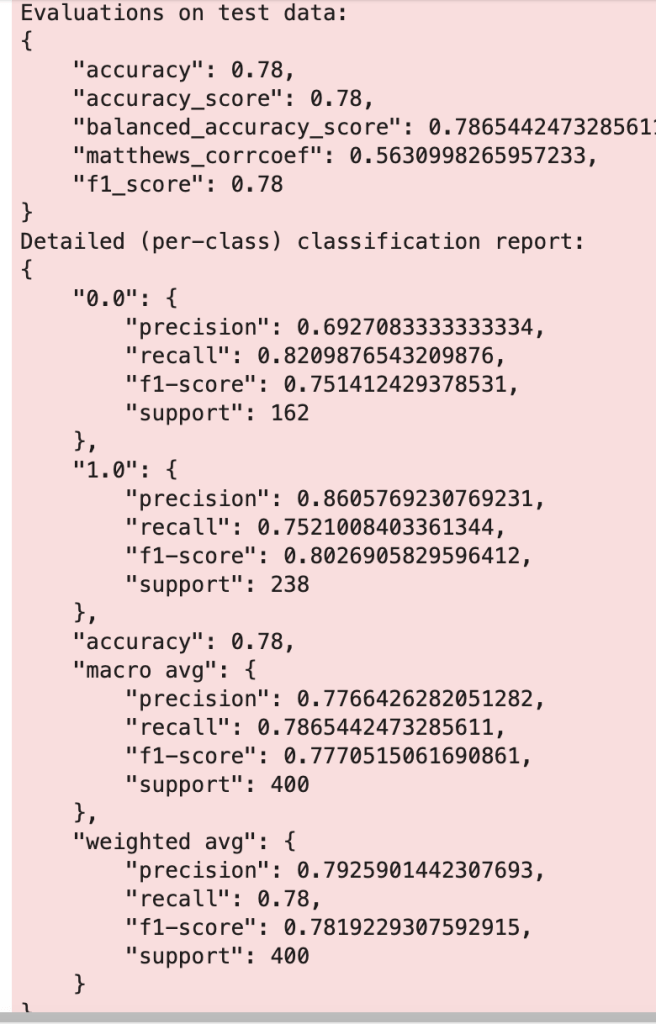
Ok, now that makes a bit more sense.
We can even look backward and check on how autogluon interpreted this problem:
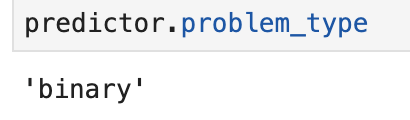

We have a binary outcome of 0 or 1 containing features that are all floats (numbers that are not necessarily whole).
What about feature importance?
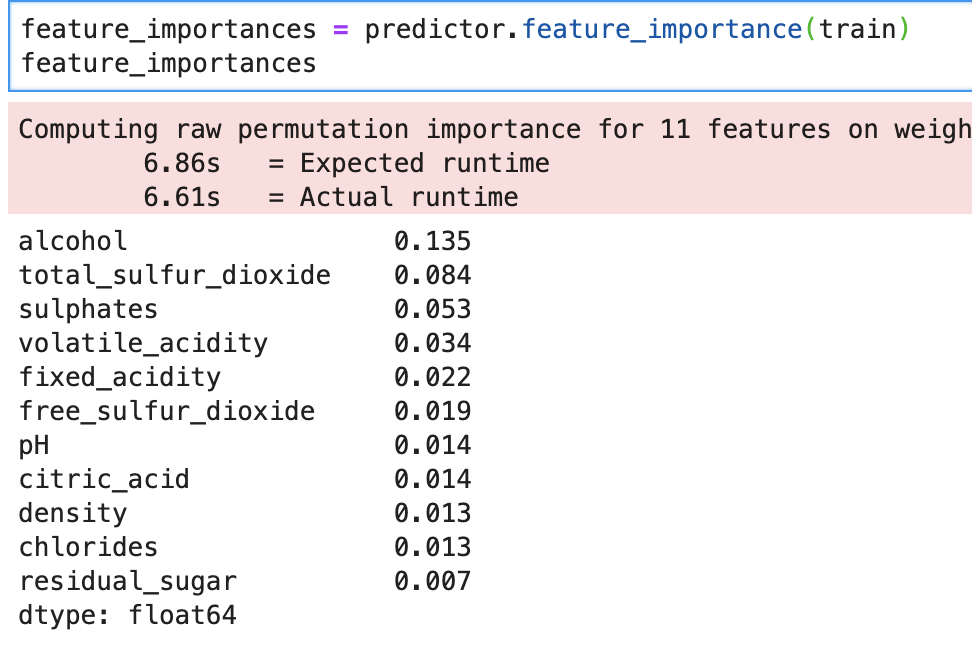
So we see our feature importances above, and run time also. This library is big on displaying run times.
Conclusion
AutoGluon is an impressive python library that can accomplish many different tasks in a short amount of time. You can probably optimize your results by doing your cleaning and preprocessing, I would imagine. Whether this means upsampling a minority class or feature selection, you still have to do some work. However, if you are looking for a quick and powerful library, AutoGluon is a great place to start.
Thanks for Reading!

