
Introduction
(PLEASE READ – Later on in this blog I describe target encoding without naming it as such. I wrote this blog before I knew target encoding was a popular thing and I am glad to have learned that it is a common encoding method. If you read later on, I will include a quick-fix target encoder as an update to the long-form one I have provided. Thanks!).
For my capstone project at the Flatiron School, where I studied data science, I decided to build a car insurance fraud detection model. When building my model, I had a lot of categorical data to address. Variables like “years as customer” are easy to address but variables like “car brand” are less easy to address as they are not numerical. However, these types of problems are nothing new or novel. Up until this point, I had always used dummy variables to address these problems. However, by adding dummy variables to my model, things got very difficult to manage. In case you are not familiar – I will give a more comprehensive explanation of what dummy variables are and what purpose they serve later. It was at this point that I started panicking. I had bad scores, a crazy amount of features, and I lacked an overall feeling of clarity and control of my project. Then things changed. I spoke with the instructors and we began to explore other types of ways to encode categorical data. I’d like to share of these ideas as well as discuss their benefits and drawbacks. I think this will be beneficial to any reader for the sake of novelty, utility, and efficiency but most importantly, you can improve your models or tell different stories depending on how you choose to encode data.
Dummy Variables
Dummy variables are added features that exist only to tell you whether or not a certain instance of a variable is present in one row of data or not. If you wanted to classify colors of m&m’s using dummy variables and you had red, yellow, and blue m&m’s, then you would add a column for blue and a column for red. If the piece you are holding is red, give the red column a one and blue column a zero and vice-versa. With yellow, it is a little different, as you assign a zero to both blue and red since that automatically means your m&m in hand would be yellow. It’s important to note that just because you are using dummy variables, it does not mean that each possible instance (like colors, for example) carries the same weight (i.e. red may be more indicative of something than blue, per se). In fact, one of the great things about dummy variables is that, other than being easy, when you run some sort of feature importance or other analogous type of evaluation, you can see how important each unique instance can be. Say you are trying to figure out where the most home runs are hit every year in baseball. If you have an extra column for every single park, you can learn where many are hit and where fewer are hit. However, since you are dropping one instance for each variable, you must also consider the effect of your coefficient/feature importances on the instance you drop. For example if red and blue m&m’s have some high flavor profile, maybe yellow has a lower flavor profile and vice-versa. This relates to the dummy variable trap which is basically a situation where you may lose some information since you always must drop at least one instance of a variable to avoid multicollinearity/autocorrelation. To get back to benefits of dummy variables, you can search for feature interactions by multiplying, for example, two or more dummy variables together to create a new feature. However, this relates to one problem with dummy variables. If you have a lot of unique instances of a particular feature, you will inevitably add many many columns. Let’s say you want to know the effect of being born in anytime between 1900 and 2020 on life expectancy. That’s a lot of dummy columns to add. Seriously, a lot. I see two solutions to this dilemma. Don’t use dummy variables at all, as we will soon discuss, or just be selective on which features are best fit for dummies based on intuition. If you think about it, there is also another reason to limit the amount of columns you add; over-fitting. Imagine, for a second, that you want to know life expectancy based on every day between 1500 and 2020. That’s a lot of days. You can still do this inquiry effectively, so don’t worry about that, but using dummies is inefficient. You may want to bin your data or do another type of encoding as we will discuss later. (One-hot encoding is a very similar process. The difference there is that one-hot encoding you don’t drop the “extra” column and have a binary output for each instance).
Integer / Label Encoding

One simple way of making all your data numerical without adding extra confusing features is by assigning a value to each instance. For example, red = 0, blue = 1, yellow = 2. By doing this, your data frame maintains its original shape and you now have represented your dat numerically. One drawback here is that it blurs one’s understanding of the effect of variable magnitude as well as creating a false sense of some external order or structure. Say you have 80 colors in your data and not just 3. How do we pick our order and what does our order imply? Why would one color be first as opposed to 51st? In addition, wouldn’t color 80 have some larger scale impact just by virtue of being color 80 and not color 1. Let’s say color 80 is maroon and color 1 is red. That’s certainly misleading. So it is easy to do and is effective in certain situations but often creates more problems that solutions. (This method is not your easy way out).
Custom Dictionary Creation and Mapping
The next method is similar to the one above almost entirely, but merits discussion. Here, you use label encoding but you use some method, totally up to you, to establish meaning and order. Perhaps colors similar to each other are labeled 1 and 1.05 as opposed to 40 and 50. However, this requires some research and a lot of work to be done right and so much is undetermined as you start and therefore it is not the best method.
Binning Data and Assigning Values to Bins

Randomly assigning numerical values or carefully finding the perfect way to represent your data are not effective and/or efficient. However, one easy way to label encode in an effective way is to bin data with many unique values. Say you want to group students together. It would only be natural to draw some similarities between those getting 70.4, 75.9, and 73.2 averages and people scoring in the 90s. Here have you dealt with all the problems with label encoding in one quick step. Your labels have tell a story with a meaningful order and you don’t have to carefully examine your data to find groups. Pandas allows you to instantly bin subsets of a feature based on quantiles or other grouping methods in one line of code. After that you can create a dictionary and map it. (This is a similar process to my last suggestion). Binning also has helped me in the past to reduce overfitting and build more accurate models. Say you have groups of car buyers. While there may be differences between the people buying cars in the 20k-50k range compared to the 50k-100k range, there are probably far less differences between buyers in the 300k-600k range. That interval is 6 times as big as the 50k-100k range and there are probably fewer members than the previous to ranges. You can easily capture that divide if you just bin the 300k-600k buyers together and you will likely have a worse model if you don’t. You can take this idea of binning to the next level and add even more meaning to your encoding by combining binning with my final suggestion. (First bin, next follow my final suggestion)
Mapping (Mean) Value Based on Correlation with Target Variable (and Other Variations)
“Mapping (Mean) Value Based on Correlation with Target Variable (and Other Variations)” is a lot of words to digest and probably sounds confusing, so I will break this down and explain it using a visual. So first I’ll explain what I mean. For my explanation, I will use an example. I first came across this method studying car insurance fraud as discussed above. I found that ~25% of my reports survey were fraud, which was surprisingly high. Armed with this knowledge, I was now ready to use it to identify and replace my categorical features with meaningful numerical values. Say my categorical feature was car brand. It’s quite likely that Lamborghinis and Fords are present in fraud reports at different proportions. The mean is 25%, so we should expect both brands to be close to this number. However, just assigning a Ford the number 25% accomplishes nothing. Instead if 20% of reports involving Fords were fraud, Ford now became 20%. Similarly, if Lamborghinis had a higher rate, say 35%, Lamborghinis now became known as 35%. Here’s some code to demonstrate what I mean:
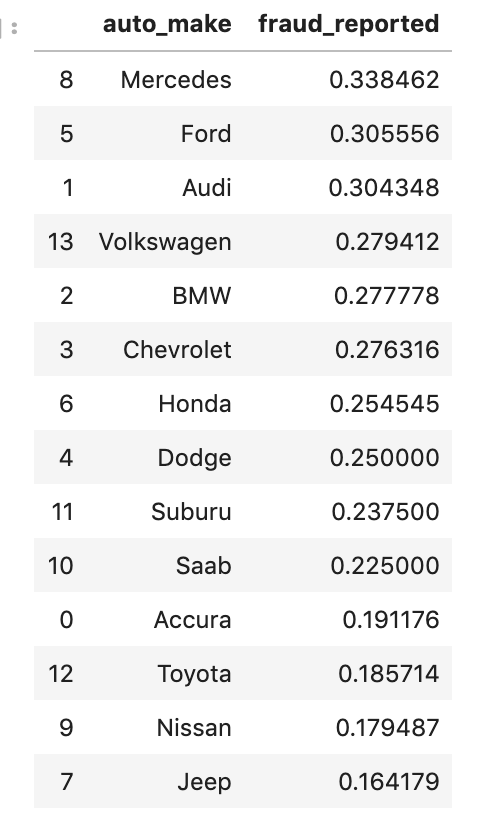
So what this process shows is that fraudulent reports are correlated more strongly with Mercedes cars and less with Jeep cars. Therefore, they are treated differently. This is a very powerful method; not only does it encode effectively, but it also solves the problem you lose when you avoid dummy variables by seeing the impact of unique instances of a variable. However, it is worth noting that you can only see each feature’s correlation with the target variable (here – insurance fraud rates) if you print out that data. If you just run a loop, everything will turn into a number. You do have to take the extra step and explore all the individual relationships. It is not that hard to do, though. What I like to do is create a two column data frame: an individual feature with the target grouped by the non-target feature (like above). I then use this information to create and map a dictionary of values. This can be scaled easily using a loop. Now, if you look back to the name of this section, I add in the words “other variations.” While I have only looked at the mean values, I imagine that you can try to use other aggregation methods like minimums and maximums (and others) to represent each unique instance of a feature. This method can also be very effective if you have already binned your data. Why assign a bunch of unique values to car buyers in the 300k-600k when you can bin them together?
Update!
This update comes around one month from the initial publishing of this blog. I describe target encoding above, but only recently learned that ‘target encoding’ was the proper name. More importantly, it can be done in one line of code. Here’s a link to the documentation so you can accomplish this task easily http://contrib.scikit-learn.org/category_encoders/targetencoder.html.
Conclusion
Categorical encoding is a very important part of any model with any qualitative data and even quantitative data at times. There are various methods of dealing with categorical data as we have explored above. While some methods may appear better than others, there is value in experimenting, optimizing your model, and using the one most appropriate or necessary methods in projects. Most of what I discussed was at a relatively simple level in the sense that I didn’t dig too deep into the code. If you look at my GitHub, you can find these types of encodings all over my code and can also find other online resources. It should be easy to find.
I’ll leave with one last note. Categorical encoding should be done later on in your notebooks. You can do EDA with encoded data, but you probably want to maintain your descriptive labels when doing the bulk of your EDA and hypothesis testing. Just to really drive this point home, I’ve got an example. If you want to know which m&m’s are most popular, it is far more beneficial to know the color than the color encoding. “Red has a high flavor rating” explains a lot to someone. “23.81 has a high flavor rating” on the other hand… well no one knows what that means, not even the person who produces that statistic. Categorical encoding should instead be though of as one of your last steps before modeling. Don’t rush.
That wraps it up. Thank you for visiting my blog!


One comment